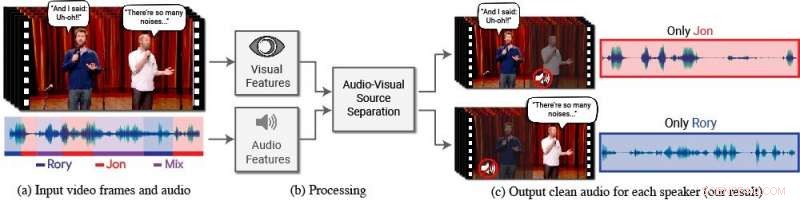
Un nouveau modèle isole et améliore la parole des locuteurs souhaités dans une vidéo. (a) L'entrée est une vidéo (images + piste audio) avec une ou plusieurs personnes parlant, où le discours d'intérêt est perturbé par d'autres locuteurs et/ou un bruit de fond. (b) Les caractéristiques audio et visuelles sont extraites et introduites dans un modèle de séparation de la parole audiovisuel commun. (c) La sortie est une décomposition de la piste audio d'entrée en pistes vocales claires, un pour chaque personne détectée dans la vidéo. Le discours de personnes spécifiques est amélioré dans les vidéos tandis que tous les autres sons sont supprimés. Le nouveau modèle a été formé à l'aide de milliers d'heures de segments vidéo du nouvel ensemble de données de l'équipe, AVSpeech, qui sera rendu public. Crédit :Auteurs/Google Images fixes :avec l'aimable autorisation de l'équipe Coco/CONAN
Les gens ont un don naturel pour se concentrer sur ce que dit une seule personne, même lorsqu'il y a des conversations concurrentes en arrière-plan ou d'autres sons distrayants. Par exemple, les gens peuvent souvent comprendre ce qui est dit par quelqu'un dans un restaurant bondé, lors d'une fête bruyante, ou en regardant des débats télévisés où plusieurs experts se parlent. À ce jour, être capable d'imiter informatiquement et avec précision cette capacité humaine naturelle à isoler la parole a été une tâche difficile.
« Les ordinateurs comprennent de mieux en mieux la parole, mais ont encore des difficultés importantes à comprendre la parole lorsque plusieurs personnes parlent ensemble ou lorsqu'il y a beaucoup de bruit, " dit Ariel Ephrat, un doctorat candidat à l'Université hébraïque de Jérusalem-Israël et auteur principal de la recherche. (Ephrat a développé le nouveau modèle lors d'un stage chez Google à l'été 2017.) "Nous, les humains, savons naturellement comment comprendre la parole dans de telles conditions, mais nous voulons que les ordinateurs puissent le faire aussi bien que nous, peut-être encore mieux."
À cette fin, Ephrat et ses collègues de Google ont développé un nouveau modèle audiovisuel pour isoler et améliorer la parole des locuteurs souhaités dans une vidéo. Le modèle basé sur le réseau profond de l'équipe intègre à la fois des signaux visuels et auditifs afin d'isoler et d'améliorer n'importe quel haut-parleur dans n'importe quelle vidéo, même dans des scénarios difficiles du monde réel, comme la visioconférence, où plusieurs participants parlent souvent en même temps, et bars bruyants, qui pourrait contenir une variété de bruits de fond, musique, et des conversations concurrentes.
L'équipe, qui comprend Inbar Mosseri de Google, Oran Lang, Tali Dekel, Kévin Wilson, Avinatan Hassidim, William T. Freeman, et Michael Rubinstein, présenteront leur travail au SIGGRAPH 2018, du 12 au 16 août à Vancouver, Colombie britannique. La conférence et l'exposition annuelles présentent les plus grands professionnels du monde, universitaires, et des esprits créatifs à la pointe de l'infographie et des techniques interactives.
Dans ce travail, les chercheurs ne se sont pas seulement concentrés sur les indices auditifs pour séparer la parole, mais aussi sur les indices visuels dans la vidéo, c'est-à-dire les mouvements des lèvres du sujet et potentiellement d'autres mouvements du visage qui peuvent prêter à ce qu'il dit. Les caractéristiques visuelles recueillies sont utilisées pour « concentrer » l'audio sur un seul sujet qui parle et pour améliorer la qualité de la séparation de la parole.
Pour former leur modèle audiovisuel commun, Ephrat et ses collaborateurs ont organisé un nouvel ensemble de données, " AVSpeech, " composé de milliers de vidéos YouTube et d'autres segments de vidéos en ligne, comme les TED Talks, vidéos explicatives, et des conférences de qualité. Depuis AVSpeech, les chercheurs ont généré un ensemble de formation de soi-disant « cocktails synthétiques » – des mélanges de vidéos de visage avec un discours clair et d'autres pistes audio vocales avec un bruit de fond. Pour isoler la parole de ces vidéos, l'utilisateur n'est tenu de spécifier que le visage de la personne dans la vidéo dont l'audio doit être distingué.
Dans plusieurs exemples détaillés dans le document, intitulé « Looking to Listen at the Cocktail Party:A Speaker-Independent Audio-Visual Model for Speech Separation, " la nouvelle méthode a donné des résultats supérieurs par rapport aux méthodes audio uniquement existantes sur des mélanges de parole pure, et des améliorations significatives dans la fourniture d'un son clair à partir de mélanges contenant de la parole et du bruit de fond qui se chevauchent dans des scénarios du monde réel. Bien que le travail soit axé sur la séparation et l'amélioration de la parole, la nouvelle méthode de l'équipe pourrait également être appliquée à la reconnaissance automatique de la parole (ASR) et à la transcription vidéo, c'est-à-dire capacités de sous-titrage codé sur les vidéos en streaming et la télévision. Dans une manifestation, le nouveau modèle audiovisuel commun a produit des sous-titres plus précis dans les scénarios où deux locuteurs ou plus étaient impliqués.
Surpris d'abord par le bon fonctionnement de leur méthode, les chercheurs sont enthousiasmés par son potentiel futur.
« Nous n'avons jamais vu la séparation de la parole effectuée 'dans la nature' avec une telle qualité auparavant. C'est pourquoi nous voyons un avenir passionnant pour cette technologie, " note Ephrat. " Il y a encore du travail à faire avant que cette technologie n'arrive entre les mains des consommateurs, mais avec les résultats préliminaires prometteurs que nous avons montrés, nous pouvons certainement le voir prendre en charge une gamme d'applications à l'avenir, comme le sous-titrage vidéo, vidéo conférence, et même des aides auditives améliorées si de tels appareils pouvaient être combinés avec des caméras."
Les chercheurs explorent actuellement les possibilités de l'intégrer dans divers produits Google.














