Nous dépendons de catalyseurs pour transformer notre lait en yaourt, pour produire des post-it à partir de pâte à papier et pour exploiter des sources d'énergie renouvelables comme les biocarburants. Trouver des matériaux catalytiques optimaux pour des réactions spécifiques nécessite des expériences laborieuses et des calculs de chimie quantique intensifs en calculs.
Souvent, les scientifiques se tournent vers les réseaux de neurones graphiques (GNN) pour capturer et prédire la complexité structurelle des systèmes atomiques, un système efficace seulement après que la conversion méticuleuse des structures atomiques 3D en coordonnées spatiales précises sur le graphique soit terminée.
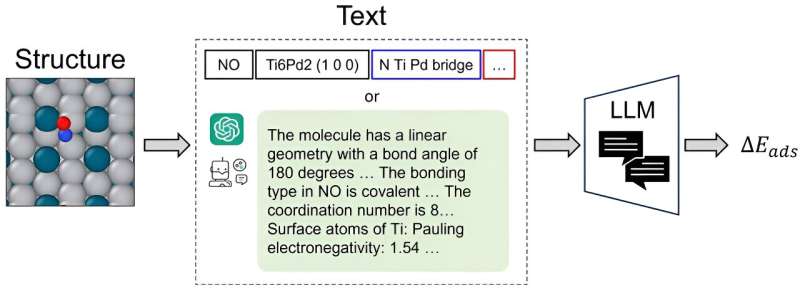
CatBERTa, un modèle de transformateur de prédiction énergétique, a été développé par des chercheurs de la faculté d'ingénierie de l'université Carnegie Mellon comme approche pour aborder la prédiction des propriétés moléculaires à l'aide de l'apprentissage automatique.
"Il s'agit de la première approche utilisant un grand modèle de langage (LLM) pour cette tâche, nous ouvrons donc une nouvelle voie de modélisation", a déclaré Janghoon Ock, Ph.D. candidat dans le laboratoire d'Amir Barati Farimani.
Un différenciateur clé est la capacité du modèle à utiliser directement du texte (langage naturel) sans aucun prétraitement pour prédire les propriétés du système adsorbat-catalyseur. Cette méthode est particulièrement bénéfique car elle reste facilement interprétable par les humains, permettant aux chercheurs d'intégrer de manière transparente des caractéristiques observables dans leurs données.
De plus, l’application du modèle de transformateur dans leurs recherches offre des informations substantielles. Les scores d'auto-attention, en particulier, sont cruciaux pour améliorer leur compréhension de l'interprétabilité dans ce cadre.
"Je ne peux pas dire que ce sera une alternative aux GNN de pointe, mais nous pouvons peut-être l'utiliser comme approche complémentaire", a déclaré Ock. "Comme on dit :"Plus on est de fous, plus on est de fous"."
Le modèle offre une précision prédictive comparable à celle obtenue par les versions antérieures des GNN. Notamment, CatBERTa a eu plus de succès lorsqu’il a été formé sur des ensembles de données de taille limitée. De plus, CatBERTa a surpassé les capacités d'annulation d'erreurs des GNN existants.
L'équipe s'est concentrée sur l'énergie d'adsorption mais a déclaré que l'approche peut être étendue à d'autres propriétés, telles que l'écart HOMO-LUMO et les stabilités liées aux systèmes adsorbat-catalyseur, étant donné un ensemble de données approprié.
En intégrant les capacités de modèles de langage étendus aux exigences de la découverte de catalyseurs, l’équipe vise à rationaliser le processus de sélection efficace des catalyseurs. Ock travaille à améliorer la précision du modèle.
Les résultats sont publiés dans la revue ACS Catalysis .
Plus d'informations : Janghoon Ock et al, Prédiction de l'énergie catalytique avec CatBERTa : dévoilement de stratégies d'exploration de fonctionnalités via de grands modèles linguistiques, Catalyse ACS (2023). DOI :10.1021/acscatal.3c04956
Informations sur le journal : Catalyse ACS
Fourni par le génie mécanique de l'Université Carnegie Mellon