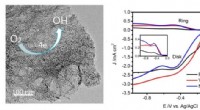
Représentation d'un artiste d'une cellule bactérienne. Crédit : Centers for Disease Control and Prevention/James Archer
Dans une première pour les algorithmes d'apprentissage automatique, un nouveau logiciel développé à Caltech peut prédire le comportement des bactéries en lisant le contenu d'un gène. Cette percée pourrait avoir des implications importantes pour notre compréhension de la biochimie bactérienne et pour le développement de nouveaux médicaments.
L'un des axes de la pharmacologie moderne est axé sur le soulagement des maladies en développant des médicaments qui ciblent des protéines spécifiques qui résident dans les membranes des cellules de notre corps. Ces protéines, appelées protéines membranaires intégrales (IMP), agissent comme des récepteurs ou des « portes » qui permettent aux matériaux d'entrer et de sortir des cellules. Des exemples d'IMP sont les récepteurs couplés aux protéines G, qui relayent des informations à une cellule sur son environnement, et canaux ioniques, qui contrôlent l'environnement intérieur d'une cellule en agissant comme des gardiens qui permettent sélectivement aux ions d'entrer et de sortir de la cellule. Les PMI sont les cibles de près de 50 pour cent de tous les médicaments sur le marché. Malheureusement, de nombreux PMI sont mal compris.
"Ce sont des molécules très importantes que notre corps fabrique et que nous ne connaissons tout simplement pas assez, " dit Bil Clemons, professeur de biochimie à Caltech.
Afin d'acquérir une compréhension plus complète d'un IMP, les chercheurs doivent en générer de grandes quantités pour la purification et l'étude détaillée. Typiquement, cela se fait en insérant l'ADN de cette protéine dans des bactéries ; la protéine est ensuite produite naturellement au fur et à mesure que les bactéries se développent et se multiplient. Le problème est que toutes les bactéries ne sont pas disposées à coopérer et ne produisent que de maigres quantités de protéines. Seules quelques bactéries finissent par fabriquer suffisamment de protéines pour être utiles, et, jusqu'à maintenant, il n'y avait aucun moyen pour les chercheurs de savoir si une bactérie avec laquelle ils travaillent sera un succès ou un raté.
"L'une des principales limites de l'étude des protéines membranaires est le manque de capacité à les exprimer en quantités raisonnables, " dit Clemons. " Nous utilisons ces bactéries comme des usines pour fabriquer des choses pour nous, mais c'est aléatoire... la plupart du temps, raté. Pour l'anecdote, ça a été un succès d'environ 10 pour cent."
Tous les essais et erreurs impliqués dans la coopération des bactéries font perdre du temps et des ressources aux chercheurs. Clemons s'est demandé s'il serait possible d'utiliser des ordinateurs pour prédire comment les bactéries réagiront lorsqu'on leur demandera de créer une protéine qu'elles ne produisent normalement pas.
"Nous avons supposé que les cellules bactériennes faisaient une lecture quantitative de l'ADN pour déterminer la quantité de ces protéines à fabriquer, " dit-il. " Nous voulions savoir si nous pouvions utiliser des outils informatiques pour augmenter le taux de réussite de la recherche de bactéries qui expriment des protéines en quantités utiles pour nous aider à caractériser des molécules importantes pour la médecine. "
Clemons et son étudiant diplômé, Shyam Saladi, a créé cet outil - un logiciel d'apprentissage automatique qu'ils ont baptisé IMProve - qui compare l'ADN bactérien avec des données sur la quantité de protéines produites par la bactérie. Ils ont ensuite utilisé un ensemble de données pour IMProve qui a cultivé de nombreux échantillons de bactéries pour voir dans quelle mesure elles produisaient les protéines membranaires souhaitées. Les chercheurs ont formé IMProve en alimentant ces résultats et les codes génétiques sur lesquels les bactéries s'appuient pour exprimer les protéines dans IMProve afin qu'il puisse apprendre quelles séquences d'ADN allaient entraîner une production élevée de protéines.
Une fois le logiciel formé, les chercheurs ont découvert qu'il prédisait si bien le comportement bactérien qu'ils étaient capables de doubler leur taux de sélection réussie de bactéries qui exprimeraient des IMP en grande quantité.
"Cela nous a surpris car il n'y avait aucune garantie que cette approche allait fonctionner, " dit Clemons. " Les cellules sont extrêmement complexes, et vous demandez à un modèle statistique relativement simple de prédire ce qu'une cellule va faire. De ce point de vue, c'était assez choquant."
Mais, Clemons ajoute que, peut-être que leurs résultats ne sont pas si surprenants avec le recul.
"Cela souligne l'idée que les cellules ne sont que des ordinateurs, et ils ne font que calculer des choses, " il dit.
Le papier, intitulé "Un modèle statistique pour l'expression améliorée des protéines membranaires à l'aide de caractéristiques dérivées de séquences, " apparaît dans le numéro du 30 mars du Journal de chimie biologique .