L'ARN, ou acide ribonucléique, est l'un des deux acides nucléiques trouvés dans la nature. L'autre, l'acide désoxyribonucléique (ADN), est certainement plus figé dans l'imagination. Même les personnes peu intéressées par la science ont une idée que l'ADN est vital dans la transmission des traits d'une génération à la suivante, et que l'ADN de chaque être humain est unique (et c'est donc une mauvaise idée de laisser sur une scène de crime). Mais pour toute la notoriété de l'ADN, l'ARN est une molécule plus polyvalente, se présentant sous trois formes principales: l'ARN messager (ARNm), l'ARN ribosomal (ARNr) et l'ARN de transfert (ARNt).
Le travail de l'ARNm dépend fortement sur les deux autres types, et l'ARNm se trouve carrément au centre du soi-disant dogme central de la biologie moléculaire (l'ADN engendre l'ARN, qui à son tour engendre des protéines).
Acides nucléiques: un aperçu
ADN et l'ARN sont des acides nucléiques, ce qui signifie qu'il s'agit de macromolécules polymères, dont les constituants monomères sont appelés nucléotides. Les nucléotides se composent de trois parties distinctes: un sucre pentose, un groupe phosphate et une base azotée, choisis parmi quatre choix. Un sucre pentose est un sucre qui comprend une structure cyclique à cinq atomes.
Trois différences majeures distinguent l'ADN de l'ARN. Tout d'abord, dans l'ARN, la partie sucre du nucléotide est le ribose, tandis que dans l'ADN, il s'agit du désoxyribose, qui est simplement du ribose avec un groupe hydroxyle (-OH) retiré de l'un des carbones du cycle à cinq atomes et remplacé par un hydrogène atome (-H). Ainsi, la partie sucre de l'ADN n'est qu'un atome d'oxygène moins massif que l'ARN, mais l'ARN est une molécule beaucoup plus chimiquement réactive que l'ADN en raison de son seul groupe -OH supplémentaire. Deuxièmement, l'ADN est, plutôt célèbre, à double brin et enroulé en une forme hélicoïdale dans sa forme la plus stable. L'ARN, d'autre part, est simple brin. Et troisièmement, alors que l'ADN et l'ARN contiennent tous deux les bases azotées adénine (A), cytosine (C) et guanine (G), la quatrième de ces bases dans l'ADN est la thymine (T) tandis que dans l'ARN, c'est l'uracile (U).
Parce que l'ADN est double brin, les scientifiques savent depuis le milieu des années 1900 que ces bases azotées s'apparient avec et seulement avec un autre type de base; Une paire avec T et une paire C avec G. En outre, A et G sont chimiquement classés comme purines, tandis que C et T sont appelés pyrimidines. Parce que les purines sont sensiblement plus grandes que les pyrimidines, un appariement A-G serait trop volumineux, alors qu'un appariement C-T serait inhabituellement sous-dimensionné; ces deux situations perturberaient les deux brins de l'ADN double brin étant à la même distance l'un de l'autre en tous points le long des deux brins.
En raison de ce schéma d'appariement, les deux brins d'ADN sont appelés "complémentaires ", et la séquence de l'un peut être prédite si l'autre est connue. Par exemple, si une chaîne de dix nucléotides dans un brin d'ADN a la séquence de base AAGCGTATTG, le brin d'ADN complémentaire aura la séquence de base TTCGCATAAC. Parce que l'ARN est synthétisé à partir d'une matrice d'ADN, cela a également des implications pour la transcription.
Structure de base de l'ARN
L'ARNm est la forme d'acide ribonucléique la plus "semblable à l'ADN" car son travail est en grande partie le même: transmettre les informations codées dans les gènes, sous forme de bases azotées soigneusement ordonnées, à la machinerie cellulaire qui assemble les protéines. Mais divers types vitaux d'ARN existent également.
La structure tridimensionnelle de l'ADN a été élucidée en 1953, ce qui a valu à James Watson et Francis Crick un prix Nobel. Mais pendant des années après, la structure de l'ARN est restée insaisissable malgré les efforts de certains des mêmes experts en ADN pour le décrire. Dans les années 1960, il est devenu clair que bien que l'ARN soit simple brin, sa structure secondaire - c'est-à-dire la relation de la séquence de nucléotides les uns avec les autres lorsque l'ARN s'enroule dans l'espace - implique que les longueurs d'ARN peuvent se replier dans sur eux-mêmes, avec des bases dans le même brin se liant ainsi les uns aux autres de la même manière une longueur de ruban adhésif pourrait se coller à elle-même si vous la laissez se plier. C'est la base de la structure en forme de croix de l'ARNt, qui comprend trois coudes à 180 degrés qui créent l'équivalent moléculaire des culs-de-sac dans la molécule.
L'ARNr est quelque peu différent. Tout l'ARNr est dérivé d'un monstre d'un brin d'ARNr d'environ 13 000 nucléotides de long. Après un certain nombre de modifications chimiques, ce brin est clivé en deux sous-unités inégales, l'une appelée 18S et l'autre étiquetée 28S. («S» signifie «unité Svedberg», une mesure que les biologistes utilisent pour estimer indirectement la masse des macromolécules.) La partie 18S est incorporée à ce qu'on appelle la petite sous-unité ribosomale (qui, lorsqu'elle est terminée, est en fait 30S) et la partie 28S contribue à la grande sous-unité (qui au total a une taille de 50S); tous les ribosomes contiennent une de chaque sous-unité ainsi qu'un certain nombre de protéines (pas des acides nucléiques, ce qui rend les protéines elles-mêmes possibles) pour fournir aux ribosomes une intégrité structurelle.
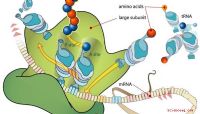
Les brins d'ADN et d'ARN ont tous deux ce qu'on appelle 3 'et 5 '("trois-prime" et "cinq-prime") se termine sur la base des positions des molécules attachées à la portion de sucre du brin. Dans chaque nucléotide, le groupe phosphate est attaché à l'atome de carbone marqué 5 'dans son cycle, tandis que le carbone 3' comporte un groupe hydroxyle (-OH). Lorsqu'un nucléotide est ajouté à une chaîne d'acide nucléique en croissance, cela se produit toujours à l'extrémité 3 'de la chaîne existante. C'est-à-dire que le groupe phosphate à l'extrémité 5 'du nouveau nucléotide est joint au carbone 3' comportant le groupe hydroxyle avant que cette liaison ne se produise. Le -OH est remplacé par le nucléotide, qui perd un proton (H) de son groupe phosphate; ainsi une molécule de H 2O, ou eau, est perdue dans l'environnement dans ce processus, faisant de la synthèse d'ARN un exemple d'une synthèse de déshydratation. La transcription est le processus dans lequel l'ARNm est synthétisé à partir d'une matrice d'ADN. En principe, compte tenu de ce que vous savez maintenant, vous pouvez facilement imaginer comment cela se produit. L'ADN est double brin, de sorte que chaque brin peut servir de matrice pour l'ARN simple brin; ces deux nouveaux brins d'ARN, en raison des aléas de l'appariement de bases spécifiques, seront complémentaires l'un de l'autre, non pas qu'ils se lieront ensemble. La transcription de l'ARN est très similaire à la réplication de l'ADN dans la mesure où les mêmes règles d'appariement de bases s'appliquent, U remplaçant T dans l'ARN. Notez que ce remplacement est un phénomène unidirectionnel: T dans l'ADN code toujours pour A dans l'ARN, mais A dans l'ADN code pour U dans l'ARN. Pour que la transcription se produise, la double hélice d'ADN doit être déroulée, ce qu'il fait sous la direction d'enzymes spécifiques. (Il reprend plus tard sa conformation hélicoïdale appropriée.) Après cela, une séquence spécifique appelée à juste titre la séquence du promoteur signale où la transcription doit commencer le long de la molécule. Cela appelle à la scène moléculaire une enzyme appelée ARN polymérase, qui à ce moment fait partie d'un complexe promoteur. Tout cela se produit comme une sorte de mécanisme biochimique à sécurité intégrée pour empêcher la synthèse d'ARN de commencer au mauvais endroit sur l'ADN et ainsi produire un brin d'ARN qui contient un code illégitime. L'ARN polymérase "lit" le brin d'ADN à partir de la séquence du promoteur et se déplace le long du brin d'ADN, ajoutant des nucléotides à l'extrémité 3 'de l'ARN. Sachez que les brins d'ARN et d'ADN, de par leur complémentarité, sont également antiparallèles. Cela signifie que lorsque l'ARN croît dans la direction 3 ', il se déplace le long du brin d'ADN à l'extrémité 5' de l'ADN. Ceci est un point mineur mais souvent déroutant pour les étudiants, vous pouvez donc consulter un diagramme pour vous assurer que vous comprenez les mécanismes de la synthèse de l'ARNm. Les liens créés entre les groupes phosphate d'un nucléotide et le sucre le groupe suivant est appelé liaisons phosphodiester (prononcé "phos-pho-die-es-ter," pas "phos-pho-dee-ster" comme il peut être tentant de le supposer). L'ARN de l'enzyme la polymérase se présente sous de nombreuses formes, bien que les bactéries n'en incluent qu'un seul type. Il s'agit d'une grande enzyme, composée de quatre sous-unités protéiques: alpha (α), bêta (β), bêta-prime (β ′) et sigma (σ). Ensemble, ceux-ci ont un poids moléculaire d'environ 420 000 Daltons. (Pour référence, un seul atome de carbone a un poids moléculaire de 12; une seule molécule d'eau, 18; et une molécule de glucose entière, 180.) L'enzyme, appelée holoenzyme lorsque les quatre sous-unités sont présentes, est chargée de reconnaître le promoteur séquences sur l'ADN et séparant les deux brins d'ADN. L'ARN polymérase se déplace le long du gène à transcrire en ajoutant des nucléotides au segment d'ARN en croissance, un processus appelé allongement. Ce processus, comme tant d'autres dans les cellules, nécessite l'adénosine triphosphate (ATP) comme source d'énergie. L'ATP n'est vraiment rien de plus qu'un nucléotide contenant de l'adénine qui a trois phosphates au lieu d'un. La transcription cesse lorsque l'ARN polymérase en mouvement rencontre une séquence de terminaison dans l'ADN. Tout comme la séquence du promoteur peut être considérée comme l'équivalent d'un feu vert sur un feu de circulation, la séquence de terminaison est l'analogue d'un feu rouge ou d'un panneau d'arrêt. Lorsqu'une molécule d'ARNm portant les informations d'une protéine particulière - c'est-à-dire un morceau d'ARNm correspondant à un gène - est terminée, elle doit encore être traitée avant d'être prête à faire son travail de délivrance d'un plan chimique aux ribosomes, où la synthèse des protéines a lieu. Dans les organismes eucaryotes, il migre également hors du noyau (les procaryotes n'ont pas de noyau). De manière critique, les bases azotées transportent des informations génétiques en groupes de trois, appelés codons triplets. Chaque codon contient des instructions pour ajouter un acide aminé particulier à une protéine en croissance. Tout comme les nucléotides sont les unités monomères des acides nucléiques, les acides aminés sont les monomères des protéines. Parce que l'ARN contient quatre nucléotides différents (en raison des quatre bases différentes disponibles) et un codon se compose de trois nucléotides consécutifs, il y a 64 codons triplets totaux disponibles (4 3 \u003d 64). Autrement dit, en commençant par AAA, AAC, AAG, AAU et jusqu'à UUU, il y a 64 combinaisons. Cependant, les humains n'utilisent que 20 acides aminés. En conséquence, le code triplet est dit redondant: dans la plupart des cas, plusieurs triplets codent pour le même acide aminé. L'inverse n'est pas vrai - c'est-à-dire que le même triplet ne peut pas coder pour plus d'un acide aminé. Vous pouvez probablement imaginer le chaos biochimique qui s'ensuivrait autrement. En fait, les acides aminés leucine, arginine et sérine ont chacun six triplets qui leur correspondent. Trois codons différents sont des codons STOP, similaires aux séquences de terminaison de transcription dans l'ADN. La traduction elle-même est un processus hautement coopératif, réunissant tous les membres de la famille d'ARN étendue. Parce qu'il se produit sur les ribosomes, il implique évidemment l'utilisation d'ARNr. Les molécules d'ARNt, décrites précédemment comme de minuscules croisements, sont responsables du transport des acides aminés individuels vers le site de traduction sur le ribosome, chaque acide aminé étant entraîné par sa propre marque spécifique d'escorte d'ARNt. Comme la transcription, la traduction a des phases d'initiation, d'allongement et de terminaison, et à la fin de la synthèse d'une molécule de protéine, la protéine est libérée du ribosome et emballée dans des corps de Golgi pour être utilisée ailleurs, et le ribosome lui-même se dissocie en ses sous-unités composantes.
Transcription: Encoder le Message en ARNm
Traduction: Décodage du message de l'ARNm