Alors que les systèmes de traduction actuels ne peuvent générer que des sorties vocales traduites ou des sous-titres textuels pour le contenu vidéo, le protocole de traduction automatique face à face peut synchroniser le visuel, Ainsi, le style de voix et le mouvement des lèvres correspondent à la langue cible. Prajwal Renukanand
Alors que les systèmes de traduction actuels ne peuvent générer que des sorties vocales traduites ou des sous-titres textuels pour le contenu vidéo, le protocole de traduction automatique face à face peut synchroniser le visuel, Ainsi, le style de voix et le mouvement des lèvres correspondent à la langue cible. Prajwal Renukanand Une équipe de chercheurs en Inde a mis au point un système pour traduire des mots dans une langue différente et faire apparaître que les lèvres d'un locuteur se déplacent en synchronisation avec cette langue.
Traduction automatique en face à face, comme décrit dans ce document d'octobre 2019, est une avancée par rapport à la traduction texte-à-texte ou parole-parole, car il ne traduit pas seulement la parole, mais fournit également une image faciale synchronisée avec les lèvres.
Pour comprendre comment cela fonctionne, regardez la vidéo de démonstration ci-dessous, créé par les chercheurs. À 6h38, vous verrez un clip vidéo de la défunte princesse Diana dans une interview de 1995 avec le journaliste Martin Bashir, expliquer, "Je voudrais être la reine du cœur des gens, dans le coeur des gens, mais je ne me vois pas être une reine de ce pays."
Un moment plus tard, vous la verrez prononcer la même citation en hindi - avec ses lèvres en mouvement, comme si elle parlait réellement cette langue.
« Communiquer efficacement au-delà des barrières linguistiques a toujours été une aspiration majeure pour les humains du monde entier, " Prajwal K.R., un étudiant diplômé en informatique à l'Institut international des technologies de l'information à Hyderabad, Inde, explique par e-mail. Il est l'auteur principal de l'article, avec son collègue Rudrabha Mukhopadhyay.
"Aujourd'hui, Internet regorge de vidéos de visages parlants :YouTube (300 heures uploadées par jour), conférences en ligne, vidéo conférence, films, émissions de télévision et ainsi de suite, " Prajwal, qui porte son prénom, écrit. « Les systèmes de traduction actuels ne peuvent générer qu'une sortie vocale traduite ou des sous-titres textuels pour un tel contenu vidéo. Ils ne gèrent pas la composante visuelle. En conséquence, le discours traduit lorsqu'il est superposé à la vidéo, les mouvements des lèvres seraient désynchronisés avec l'audio.
"Ainsi, nous nous appuyons sur les systèmes de traduction parole-parole et proposons un pipeline qui peut prendre une vidéo d'une personne parlant dans une langue source et produire une vidéo du même locuteur parlant dans une langue cible de telle sorte que le style de voix et les mouvements des lèvres correspondent le discours de la langue cible, " dit Prajwal. " Ce faisant, le système de traduction devient holistique, et comme le montrent nos évaluations humaines dans cet article, améliore considérablement l'expérience utilisateur dans la création et la consommation de contenu audiovisuel traduit."
La traduction en face à face nécessite un certain nombre d'exploits complexes. « Vu une vidéo d'une personne qui parle, nous avons deux grands flux d'informations à traduire :l'information visuelle et l'information vocale, " explique-t-il. Ils y parviennent en plusieurs étapes majeures. " Le système transcrit d'abord les phrases du discours à l'aide de la reconnaissance automatique de la parole (ASR). Il s'agit de la même technologie que celle utilisée dans les assistants vocaux (Google Assistant, par exemple) dans les appareils mobiles." Ensuite, les phrases transcrites sont traduites dans la langue souhaitée à l'aide de modèles de traduction automatique neuronale, puis la traduction est convertie en mots parlés avec un synthétiseur de synthèse vocale - la même technologie que celle utilisée par les assistants numériques.
Finalement, une technologie appelée LipGAN corrige les mouvements des lèvres dans la vidéo originale pour correspondre au discours traduit.
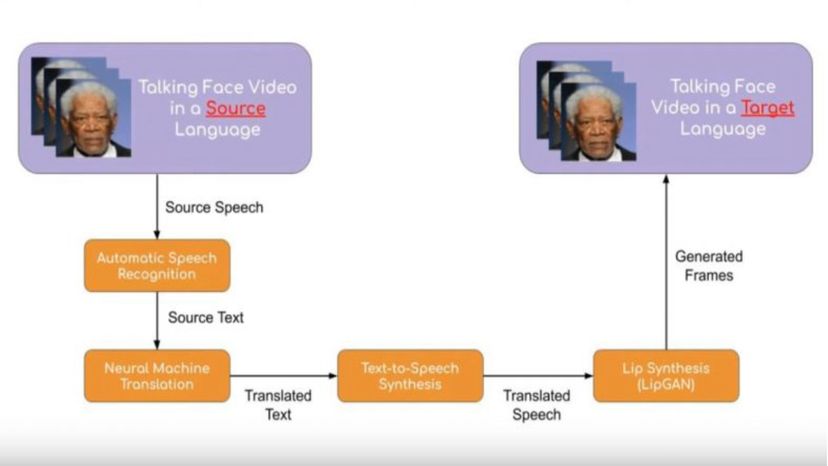 Comment la parole passe de l'entrée initiale à la sortie synchronisée. Prajwal Renukanand
Comment la parole passe de l'entrée initiale à la sortie synchronisée. Prajwal Renukanand "Ainsi, nous obtenons également une vidéo entièrement traduite avec synchronisation labiale, " explique Prajwal.
"LipGAN est la contribution novatrice clé de notre article. C'est ce qui fait entrer la modalité visuelle dans l'image. C'est le plus important car il corrige la synchronisation des lèvres dans la vidéo finale, ce qui améliore considérablement l'expérience utilisateur."
Un article, publié le 24 janvier 2020 en nouveau scientifique, a décrit la percée comme un « deepfake, " un terme désignant des vidéos dans lesquelles des visages ont été échangés ou modifiés numériquement à l'aide de l'intelligence artificielle, souvent pour créer une impression trompeuse, comme l'explique cette histoire de la BBC. Mais Prajwal maintient que c'est une représentation incorrecte de la traduction en face à face, qui n'a pas pour but de tromper, mais plutôt pour rendre le discours traduit plus facile à suivre.
"Notre travail vise principalement à élargir la portée des systèmes de traduction existants pour gérer le contenu vidéo, " explique-t-il. " Il s'agit d'un logiciel créé avec une motivation pour améliorer l'expérience utilisateur et briser les barrières linguistiques à travers le contenu vidéo. Il ouvre un très large éventail d'applications et améliore l'accessibilité de millions de vidéos en ligne."
Le plus grand défi pour faire fonctionner la traduction en face à face était le module de génération de visage. "Les méthodes actuelles pour créer des vidéos de synchronisation labiale n'étaient pas en mesure de générer des visages avec les poses souhaitées, rendant difficile le collage du visage généré dans la vidéo cible, " dit Prajwal. " Nous avons incorporé un " avant de pose " en entrée de notre modèle LipGAN, et comme résultat, nous pouvons générer un visage précis synchronisé avec les lèvres dans la pose cible souhaitée qui peut être mélangé de manière transparente dans la vidéo cible."
Les chercheurs envisagent l'utilisation de la traduction en face à face pour traduire des films et des appels vidéo entre deux personnes qui parlent chacune une langue différente. "Faire chanter/parler les personnages numériques des films d'animation est également démontré dans notre vidéo, " note Prajwal.
En outre, il prévoit que le système sera utilisé pour aider les étudiants du monde entier à comprendre les vidéos de cours en ligne dans d'autres langues. "Des millions d'étudiants en langues étrangères à travers le monde ne peuvent pas comprendre l'excellent contenu éducatif disponible en ligne, parce qu'ils sont en anglais, " il explique.
"Plus loin, dans un pays comme l'Inde avec 22 langues officielles, notre système peut, à l'avenir, traduisez le contenu des nouvelles télévisées dans différentes langues locales avec une synchronisation labiale précise des présentateurs de nouvelles. La liste des applications s'applique donc à tout type de contenu vidéo de visage parlant, qui doit être rendu plus accessible dans toutes les langues."
Bien que Prajwal et ses collègues aient l'intention d'utiliser leur percée de manière positive, la capacité de mettre des mots étrangers dans la bouche d'un orateur concerne un éminent expert américain en cybersécurité, qui craint que les vidéos altérées deviennent de plus en plus difficiles à détecter.
"Si vous regardez la vidéo, vous pouvez dire si vous regardez attentivement, la bouche a un peu de flou, " dit Anne Toomey McKenna, un éminent spécialiste du cyberdroit et des politiques à la Penn State University's Dickinson Law, et professeur à l'Institut des sciences informatiques et des données de l'université, dans un entretien par e-mail. "Cela continuera d'être minimisé à mesure que les algorithmes continueront de s'améliorer. Cela deviendra de moins en moins discernable à l'œil humain."
McKenna par exemple, imagine comment une vidéo modifiée de la commentatrice de MSNBC Rachel Maddow pourrait être utilisée pour influencer les élections dans d'autres pays, en « relayant des informations inexactes et contraires à ce qu'elle a dit ».
Prajwal s'inquiète également d'une éventuelle utilisation abusive de vidéos modifiées, mais pense que des précautions peuvent être développées pour se prémunir contre de tels scénarios, et que le potentiel positif d'amélioration de la compréhension internationale l'emporte sur les risques de la traduction automatique en face à face. (Du côté bénéfique, ce billet de blog envisage de traduire le discours de Greta Thunberg lors du sommet des Nations Unies sur le climat en septembre 2019 dans une variété de langues différentes utilisées en Inde.)
"Chaque élément technologique puissant peut être utilisé pour une énorme quantité de bien, et ont aussi des effets néfastes, " note Prajwal. " Notre travail est, En réalité, un système de traduction capable de gérer le contenu vidéo. Le contenu traduit par un algorithme n'est définitivement "pas réel, ' mais ce contenu traduit est essentiel pour les personnes qui ne comprennent pas une langue en particulier. Plus loin, au stade actuel, un tel contenu traduit automatiquement est facilement reconnaissable par les algorithmes et les téléspectateurs. Simultanément, des recherches actives sont menées pour reconnaître un tel contenu altéré. Nous pensons que l'effort collectif d'utilisation responsable, réglementation stricte, et les progrès de la recherche dans la détection des abus peuvent assurer un avenir positif à cette technologie. »
Maintenant c'est cinématographiqueSelon Language Insight, une étude menée par des chercheurs britanniques a déterminé que la préférence des cinéphiles pour les films étrangers doublés ou sous-titrés affecte le type de film vers lequel ils gravitent. Ceux qui aiment les superproductions grand public sont plus susceptibles de voir une version doublée d'un film, tandis que ceux qui préfèrent les sous-titres sont plus susceptibles d'être des fans d'importations d'art et d'essai.