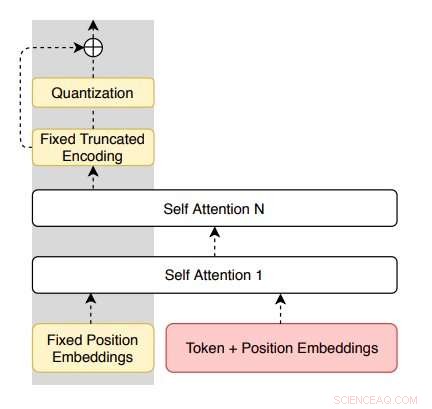
Architecture de l'encodeur proposée par les chercheurs. Crédit :Roy &Grangier.
Dans les années récentes, les chercheurs ont essayé de développer des méthodes de paraphrase automatique, qui implique essentiellement l'abstraction automatisée du contenu sémantique du texte. Jusque là, les approches qui reposent sur des techniques de traduction automatique (MT) se sont avérées particulièrement populaires en raison du manque d'ensembles de données étiquetés disponibles de paires paraphrasées.
Théoriquement, les techniques de traduction peuvent apparaître comme des solutions efficaces pour la paraphrase automatique, car ils font abstraction du contenu sémantique de sa réalisation linguistique. Par exemple, attribuer la même phrase à différents traducteurs peut entraîner des traductions différentes et un riche ensemble d'interprétations, ce qui pourrait être utile pour paraphraser des tâches.
Bien que de nombreux chercheurs aient développé des méthodes basées sur la traduction pour la paraphrase automatisée, les humains n'ont pas nécessairement besoin d'être bilingues pour paraphraser des phrases. Sur la base de ce constat, deux chercheurs de Google Research ont récemment proposé une nouvelle technique de paraphrase qui ne repose pas sur des méthodes de traduction automatique. Dans leur papier, prépublié sur arXiv, ils ont comparé leur approche monolingue à d'autres techniques de paraphrase :une traduction supervisée et une approche de traduction non supervisée.
"Ce travail propose d'apprendre des modèles de paraphrase à partir d'un corpus monolingue non étiqueté uniquement, " Aurko Roy et David Grangier, les deux chercheurs qui ont mené l'étude, écrit dans leur journal. "À cette fin, nous proposons une variante résiduelle de l'auto-encodeur variationnel à quantification vectorielle."
Le modèle introduit par les chercheurs est basé sur des auto-encodeurs à quantification vectorielle (VQ-VAE) qui peuvent paraphraser des phrases dans un cadre purement monolingue. Il a également une caractéristique unique (c'est-à-dire des connexions résiduelles parallèles au goulot d'étranglement quantifié), ce qui permet un meilleur contrôle de l'entropie du décodeur et facilite l'optimisation.
"Par rapport aux auto-encodeurs continus, notre méthode permet la génération de divers, mais des phrases proches sémantiquement d'une phrase d'entrée, " expliquent les chercheurs dans leur article.
Dans leur étude, Roy et Grangier ont comparé les performances de leur modèle avec celles d'autres approches basées sur la MT sur l'identification de paraphrases, augmentation de la génération et de la formation. Ils l'ont spécifiquement comparée à une méthode de traduction supervisée entraînée sur des données bilingues parallèles et à une méthode de traduction non supervisée entraînée sur du texte non parallèle dans deux langues différentes. Leur modèle, d'autre part, ne nécessite que des données non étiquetées dans une seule langue, celui dans lequel il paraphrase des phrases.
Les chercheurs ont découvert que leur approche monolingue surpassait les techniques de traduction non supervisée dans toutes les tâches. Des comparaisons entre leur modèle et des méthodes de traduction supervisée, d'autre part, a donné des résultats mitigés :l'approche monolingue a donné de meilleurs résultats dans les tâches d'identification et d'augmentation, tandis que la méthode de traduction supervisée était supérieure pour la génération de paraphrases.
"Globalement, nous avons montré que les modèles unilingues peuvent surpasser les modèles bilingues pour l'identification des paraphrases et l'augmentation des données par la paraphrase, " ont conclu les chercheurs. " Nous avons également signalé que la qualité de génération des modèles monolingues peut être supérieure à celle des modèles basés sur la traduction non supervisée, mais pas de traduction supervisée."
Les résultats de Roy et Grangier suggèrent que l'utilisation de données parallèles bilingues (c'est-à-dire des textes et leurs traductions possibles dans d'autres langues) est particulièrement avantageuse lors de la génération de paraphrases et conduit à des performances remarquables. Dans les situations où les données bilingues ne sont pas facilement disponibles, cependant, le modèle monolingue qu'ils proposent pourrait être une ressource utile ou une solution alternative.
© 2019 Réseau Science X














