Exemple d'image vidéo encombrée annotée à l'aide de la nouvelle méthode. Crédit :Růžička et Franchetti.
Des chercheurs de l'Université Carnegie Mellon ont récemment développé un nouveau modèle qui permet une détection rapide et précise des objets dans des séquences vidéo 4K et 8K haute résolution à l'aide de GPU. Leur méthode de pipeline d'attention effectue une évaluation en deux étapes de chaque image ou image vidéo sous une résolution approximative et raffinée, limiter le nombre total d'évaluations nécessaires.
Dans les années récentes, l'apprentissage automatique a atteint des résultats remarquables dans les tâches de vision par ordinateur, y compris la détection d'objets. Cependant, la plupart des modèles de reconnaissance d'objets fonctionnent généralement mieux sur des images avec une résolution relativement faible. Comme la résolution des appareils d'enregistrement s'améliore rapidement, il y a un besoin croissant d'outils capables de traiter des données à haute résolution.
« Nous étions intéressés à trouver et à surmonter les limites des approches actuelles, " Vit Růžička, l'un des chercheurs qui a mené l'étude a déclaré à TechXplore. « Alors que de nombreuses sources de données enregistrent en haute résolution, modèles actuels de détection d'objets à la pointe de la technologie, comme YOLO, RCNN plus rapide, SSD, etc., travailler avec des images qui ont une résolution relativement faible d'environ 608 x 608 px. Notre objectif principal était d'adapter la tâche de détection d'objets aux vidéos 4K-8K (jusqu'à 7680 x 4320 px) tout en maintenant une vitesse de traitement élevée. Nous voulions également comprendre si et dans quelle mesure nous pouvons bénéficier de la haute résolution par rapport à l'utilisation d'images en basse résolution, en termes de précision des modèles."
Le pipeline d'attention proposé par Růžička et son collègue Franz Franchetti divise la tâche de détection d'objets en deux étapes. Dans ces deux étapes, les chercheurs ont subdivisé l'image originale en la superposant avec une grille régulière, puis ont appliqué le modèle YOLO v2 pour une détection rapide des objets.
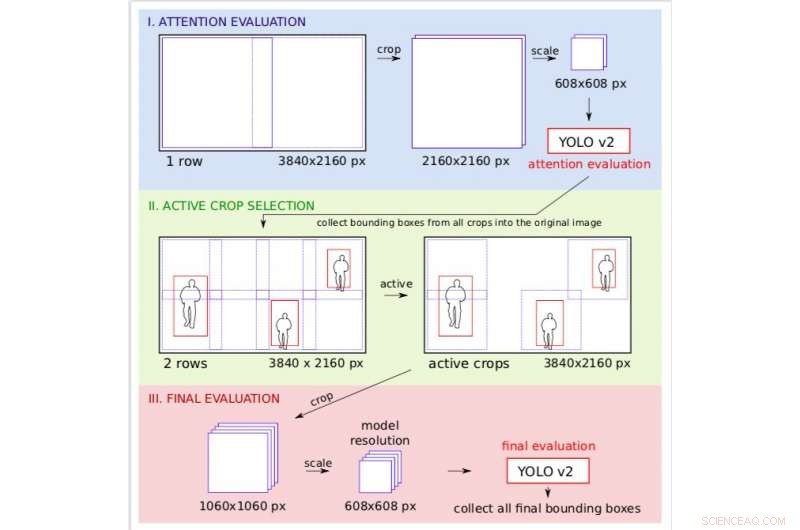
Gestion de la résolution sur l'exemple du traitement d'images vidéo 4K. Pendant l'étape d'attention, l'image est traitée sous une résolution approximative, permettant aux chercheurs de décider quelles régions de l'image devraient être actives dans une évaluation finale plus fine. Crédit :Růžička et Franchetti.
"Nous créons de nombreuses petites cultures rectangulaires, qui peut être traité par YOLO v2 sur plusieurs serveurs worker, de manière parallèle, " Růžička a expliqué. " La première étape examine l'image réduite à une résolution inférieure et effectue une détection d'objet rapide pour obtenir des cadres de délimitation grossiers. La deuxième étape utilise ces cadres de délimitation comme une carte d'attention pour décider où nous devons vérifier l'image en haute résolution. Par conséquent, lorsque certaines zones de l'image ne contiennent aucun objet d'intérêt, nous pouvons économiser sur leur traitement en haute résolution."
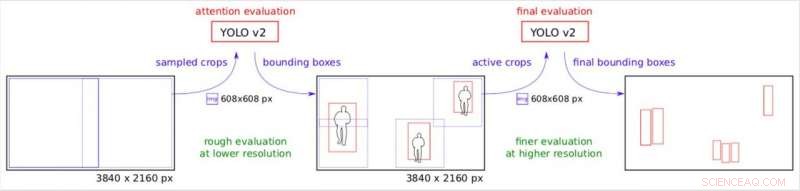
Le pipeline de l'attention. Répartition par étapes de l'image d'origine sous différentes résolutions effectives. Crédit :Růžička et Franchetti.
Les chercheurs ont implémenté leur modèle en code, répartir son travail sur les GPU. Ils ont pu maintenir une grande précision tout en atteignant une performance moyenne de trois à six ips sur les vidéos 4K et de deux ips sur les vidéos 8K. Leur méthode a donné des avantages significatifs, avec la précision moyenne mesurée sur l'ensemble de données testé passant de 33,6 AP
"Notre méthode a réduit d'environ 20 % le temps nécessaire au traitement des images haute résolution, par rapport au traitement de chaque partie de l'image originale sous haute résolution, " a déclaré Růžička. " L'implication pratique de ceci est que le traitement vidéo 4K en temps quasi réel est réalisable. Notre méthode nécessite également un nombre inférieur de serveurs pour effectuer cette tâche."
Malgré les résultats très prometteurs obtenus par cette nouvelle méthode de détection d'objets, l'utilisation d'une grille régulière recouvrant l'image originale peut donner lieu à un certain nombre de problèmes. Par exemple, cela peut parfois entraîner la réduction de moitié des objets détectés, ce qui nécessite une étape de post-traitement sur les cadres de délimitation détectés. Růžička et Franchetti explorent actuellement des moyens de résoudre et de contourner ces problèmes afin d'améliorer encore leur modèle.
© 2018 Réseau Science X