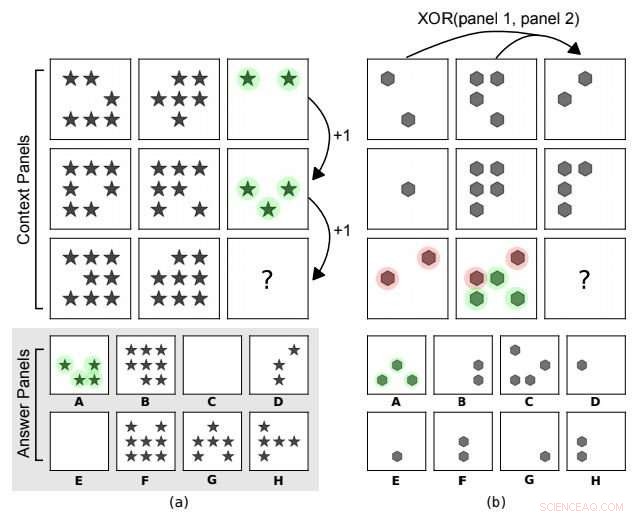
Matrices progressives de style Raven. Dans (a) la règle abstraite sous-jacente est une progression arithmétique sur le nombre de formes le long des colonnes. En (b), il existe une relation XOR sur les positions de forme le long des lignes (panneau 3 =XOR (panneau 1, panneau 2)). D'autres caractéristiques telles que le type de forme ne sont pas prises en compte. A est le bon choix pour les deux. Crédit :arXiv : 1807.04225 [cs.LG]
Essai, tests :DeepMind fait asseoir l'IA pour un test de QI. Bien que les résultats des performances de l'IA ne dépassent pas ou ne correspondent pas au raisonnement humain, c'est un début. Les scientifiques de l'IA reconnaissent qu'il s'est avéré difficile d'établir leur capacité à raisonner sur des concepts abstraits. DeepMind voulait voir comment l'IA pouvait fonctionner et l'équipe a proposé un ensemble de données et un défi pour sonder le raisonnement abstrait.
L'IA peut-elle égaler nos capacités de raisonnement abstrait ? Les réseaux de neurones profonds seront-ils plus à même de résoudre les problèmes de raisonnement visuel abstrait à l'avenir ? Les chercheurs de DeepMind ont certainement été sur l'affaire.
Leur papier, "Mesurer le raisonnement abstrait dans les réseaux de neurones, " est sur arXiv. Les auteurs sont David Barrett, Félix Hill, Adam Santoro, Ari Morcos, Timothée Lillicrap, de DeepMind. Vous pouvez vérifier ce qu'ils recherchaient et comment ils ont testé. L'article se concentre essentiellement sur une approche pour mesurer le raisonnement abstrait dans les machines d'apprentissage. Dans leur discussion, l'équipe a dit, Oui, il y a eu des progrès dans l'apprentissage du raisonnement et de la représentation abstraite dans les réseaux neuronaux, mais la mesure dans laquelle ces modèles présentent quelque chose comme un raisonnement abstrait général « fait l'objet de nombreux débats ».
Les modèles pour réussir devaient faire face à des régimes de généralisation dans lesquels les données d'entraînement et de test différaient. Ils ont dit qu'ils présentaient une architecture avec une structure conçue pour encourager le raisonnement. Résultats :Sac mixte. Ils ont dit que leur modèle était compétent pour certaines formes de généralisation, mais faible chez les autres.
Néanmoins, il est à noter qu'ils ont exploré des moyens de mesurer et d'obtenir un raisonnement abstrait plus fort dans les réseaux de neurones.
"Les tests de QI humain standard exigent souvent que les personnes testées interprètent des scènes visuelles simples en appliquant des principes qu'ils ont appris au cours de leur expérience quotidienne, " a déclaré un blog de DeepMind. " Nous n'avons pas encore les moyens d'exposer les agents d'apprentissage automatique à un flux similaire d'"expériences quotidiennes", ce qui signifie que nous ne pouvons pas facilement mesurer leur capacité à transférer des connaissances du monde réel aux tests de raisonnement visuel. Néanmoins, nous pouvons créer une configuration expérimentale qui utilise toujours à bon escient les tests de raisonnement visuel humain."
Ils ont ensuite construit un générateur de problèmes matriciels avec un ensemble de facteurs abstraits. L'équipe encourage davantage de recherches sur le raisonnement abstrait, et ils ont rendu leur ensemble de données accessible au public.
La question générale est de savoir si les scientifiques peuvent atteindre des capacités de raisonnement analytique semblables à celles des humains.
Bien que les résultats de leurs tests de QI aient pu être mitigés, les chercheurs ne voient pas cela comme un jeu de gagner ou d'abandonner. Ils poursuivront leurs travaux pour explorer des stratégies d'amélioration de la généralisation et explorer de futurs modèles. Comme Plongée du DSI remarqué, "Les assistants intelligents ont reçu des montagnes de données pour aider les consommateurs dans presque tous les domaines imaginables, pourtant, lorsqu'ils sont confrontés à des problèmes inconnus, ils peuvent encore échouer."
Les auteurs ont écrit, dans leur résumé, « nous proposons un ensemble de données et un défi conçus pour sonder le raisonnement abstrait, inspiré d'un test de QI humain bien connu. Pour réussir ce challenge, les modèles doivent faire face à divers «régimes» de généralisation dans lesquels les données d'entraînement et de test diffèrent de manière clairement définie. Nous montrons que les modèles populaires tels que ResNets fonctionnent mal, même lorsque les ensembles d'apprentissage et de test ne diffèrent que très peu, et nous présentons une nouvelle architecture, avec une structure conçue pour encourager le raisonnement, qui fait nettement mieux."
Plongée du DSI ont décrit leurs tests comme des tests de QI visuel. Dans le processus, les auteurs étaient intéressés de voir les performances des capacités de généralisation lorsque les données de test étaient différentes.
Associer l'IA aux capacités humaines d'abstraction continue d'être une bataille difficile.
Comme Plongée du DSI 's Alex Hickey a écrit, L'IA devrait distinguer différentes significations entre « manger des spaghettis avec du fromage » et « manger des spaghettis avec des chiens ».
Le document a commenté que tester les capacités des réseaux de neurones peut être délicat et que les réseaux de neurones ont leurs pièges, étant donné leur capacité de mémorisation et leur capacité à exploiter des indices statistiques superficiels.
© 2018 Tech Xplore