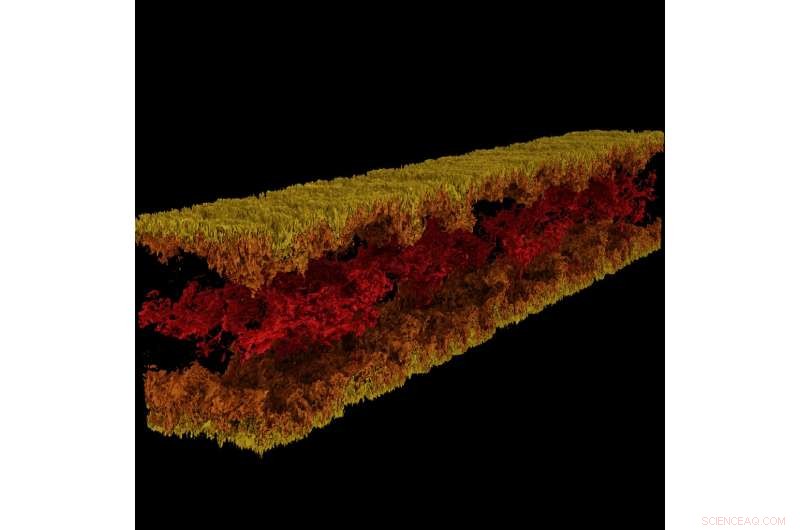
Visualisation de l'écoulement du canal turbulent produite à l'aide de GraviT. Crédit : visualisation :Texas Advanced Computing Center. Données :CIEM, L'Université du Texas à Austin.
Gros, une science percutante nécessite tout un écosystème technologique pour progresser. Cela comprend des systèmes informatiques de pointe, stockage de grande capacité, réseaux haut débit, Puissance, refroidissement... la liste s'allonge encore et encore.
De manière critique, cela nécessite également des logiciels de pointe :des programmes qui fonctionnent ensemble de manière transparente pour permettre aux scientifiques et aux ingénieurs de répondre à des questions difficiles, partager leurs solutions, et mener des recherches avec le maximum d'efficacité et le minimum de douleur.
Pour nourrir ce mode critique de progrès scientifique, en 2012, la NSF a créé le programme Software Infrastructure for Sustained Innovation (SI2), dans le but de transformer les innovations dans la recherche et l'éducation en ressources logicielles durables faisant partie intégrante de la cyberinfrastructure.
« La découverte et l'innovation scientifiques avancent sur des voies fondamentalement nouvelles ouvertes par le développement de logiciels de plus en plus sophistiqués, ", a écrit la National Science Foundation (NSF) dans la sollicitation du programme SI2. "Le logiciel est également directement responsable de l'augmentation de la productivité scientifique et de l'amélioration significative des capacités des chercheurs."
Avec cinq prix SI2 en cours, et des rôles collaboratifs sur plusieurs autres, le Texas Advanced Computing Center (TACC) est l'un des leaders nationaux dans le développement de logiciels pour le calcul scientifique. Les chercheurs principaux du TACC présenteront leurs travaux du 30 avril au 2 mai lors de la réunion des chercheurs principaux NSF SI2 2018 à Washington, D.C.
"Une partie de la mission de TACC est d'améliorer la productivité des chercheurs utilisant nos systèmes, " dit Bill Barth, TACC directeur du calcul haute performance et ancien bénéficiaire de la subvention SI2. « Le programme SI2 nous a aidés à le faire en soutenant les efforts de développement de nouveaux outils et en étendant les outils existants avec des fonctionnalités de performance et de convivialité supplémentaires. »
Des frameworks pour la visualisation à grande échelle aux outils de parallélisation automatique et plus encore, Le logiciel développé par TACC change la façon dont les chercheurs calculent à l'avenir.
Outil de parallélisation interactif
La puissance des supercalculateurs réside principalement dans leur capacité à résoudre des équations mathématiques en parallèle. Prends un problème difficile, le diviser en ses parties constitutives, résolvez chaque partie individuellement et rassemblez à nouveau les réponses - c'est l'essence du calcul parallèle. Cependant, la tâche d'organiser son problème pour qu'il puisse être traité par un supercalculateur n'est pas facile, même pour les informaticiens expérimentés.
Ritu Arora, chercheur au TACC, a travaillé pour abaisser la barre du calcul parallèle en développant un outil capable de transformer un code série, qui ne peut utiliser qu'un seul processeur à la fois, dans un code parallèle qui peut utiliser des dizaines à des milliers de processeurs. L'outil analyse une application sérielle, sollicite des informations complémentaires auprès de l'utilisateur, applique des heuristiques intégrées, et génère une version parallèle de l'application série d'entrée.
Arora et ses collaborateurs ont déployé la version actuelle d'IPT dans le cloud afin que les chercheurs puissent l'utiliser facilement via un navigateur Web. Les chercheurs peuvent générer des versions parallèles de leur code de manière semi-automatique et tester le code parallèle pour la précision et les performances sur les ressources TACC et XSEDE, y compris Stampede2, Lonestar5, et Comète.
"L'ampleur de l'impact sociétal de l'IPT est une fonction directe de l'importance du HPC dans les STEM et les domaines non traditionnels émergents, et les défis importants auxquels les experts du domaine et les étudiants sont confrontés pour gravir la courbe d'apprentissage de la programmation parallèle, " a déclaré Arora. " En plus de réduire le temps de développement et le temps d'exécution des applications sur les plates-formes HPC, IPT réduira la consommation d'énergie et maximisera les performances fournies par les plates-formes HPC grâce à sa capacité à générer du code hybride."

GraviT a permis aux chercheurs de produire des visualisations de lancer de rayons en utilisant les données produites par Enzo, un code de simulation conçu pour les riches, calculs astrophysiques hydrodynamiques multi-physiques. Crédit :Université du Texas à Austin
À titre d'exemple des capacités d'IPT, Arora souligne un effort récent pour paralléliser une application de dynamique moléculaire (MD). En parallélisant l'application série à l'aide d'OpenMP à un haut niveau d'abstraction, c'est-à-dire sans que l'utilisateur connaisse la syntaxe de bas niveau d'OpenMP, ils ont atteint une accélération de 88 % dans le code.
Ils ont également quantifié l'impact de l'IPT en termes de productivité des utilisateurs en mesurant le nombre de lignes de code qu'un chercheur doit écrire pendant le processus de parallélisation manuelle d'une application par rapport à l'utilisation d'IPT.
"Dans nos cas de test, IPT a amélioré la productivité des utilisateurs de plus de 90 %, par rapport à l'écriture manuelle du code, et généré le code parallèle qui se situe à moins de 10 % des performances du meilleur code parallèle écrit à la main disponible pour ces applications, " a déclaré Arora. "Nous sommes très heureux de son succès jusqu'à présent."
TACC étend l'IPT pour prendre en charge des types supplémentaires d'applications série ainsi que des applications qui présentent des modèles de calcul et de communication irréguliers.
(Regardez une démonstration vidéo d'IPT dans laquelle TACC montre le processus de parallélisation d'une application de dynamique moléculaire avec le modèle de programmation OpenMP.)
Gravit
La visualisation scientifique - le processus de transformation des données brutes en images interprétables - est un aspect clé de la recherche. Cependant, cela peut être difficile lorsque vous essayez de visualiser des ensembles de données à l'échelle du pétaoctet répartis sur de nombreux nœuds d'un cluster informatique. Encore plus lorsque vous essayez d'utiliser des méthodes de visualisation avancées telles que le lancer de rayons, une technique pour générer une image en traçant le chemin de la lumière sous forme de pixels dans un plan d'image et en simulant les effets de ses rencontres avec des objets virtuels.
Pour résoudre ce problème, Paul Navratil, directeur de la visualisation chez TACC, a mené un effort pour créer GraviT, un évolutif, Framework de lancer de rayons à mémoire distribuée et bibliothèque logicielle pour les applications qui englobent des données si volumineuses qu'elles ne peuvent pas résider dans la mémoire d'un seul nœud de calcul. Les collaborateurs du projet incluent Hank Childs (Université de l'Oregon), Chuck Hansen (Université de l'Utah), Matt Turk (National Center for Supercomputing Applications) and Allen Malony (ParaTools).
GraviT works across a variety of hardware platforms, including the Intel Xeon processors and NVIDIA GPUs. It can also function in heterogeneous computing environments, par exemple, hybrid CPU and GPU systems. GraviT has been successfully integrated into the GLuRay OpenGL-based ray tracing interface, the VisIt visualization toolkit, the VTK visualization toolkit, and the yt visualization framework.
"High-fidelity rendering techniques like ray tracing improve visual analysis by providing the same spatial cues of light and shadow that we see in the world around us, but these are challenging to use in distributed contexts, " said Navratil. "GraviT enables these techniques to be used efficiently across distributed computing resources, unlocking their potential for large scale analysis and to be used in situ, where data is not written to disk prior to analysis."
(The GraviT source code is available at the TACC GitHub site ).
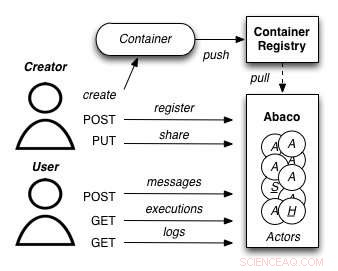
A diagram showing how the Abaco "Actor" model works. Credit:University of Texas at Austin
Abaco
The increased availability of data has enabled entirely new kinds of analyses to emerge, yielding answers to many important questions. Cependant, these analyses are complex and frequently require advanced computer science expertise to run correctly.
Joe Stubbs, who leads TACC's Cloud and Interactive Computing (CIC) group, is working on a project that simplifies how researchers create analysis tools that are reliable and scalable. Le projet, known as Abaco, adapts the "Actor" model, whereby software systems are designed as a collection of simple functions, which can then be provided as a cloud-based capability on high performance computing environments.
"Abaco significantly simplifies the way scientific software is developed and used, " said Stubbs. "Scientific software developers will find it much easier to design and implement a system. Plus loin, scientists and researchers that use software will be able to easily compose collections of actors with pre-determined functionality in order to get the computation and data they need."
The Abaco API (application programming interface) combines technologies and techniques from cloud computing, including Linux Containers and the "functions-as-a-service" paradigm, with the Actor model for concurrent computation. Investigators addressing grand challenge problems in synthetic biology, earthquake engineering and food safety are already using the tool to advance their work. Stubbs is working to extend Abaco's ability to do data federation and discoverability, so Abaco programs can be used to build federated datasets consisting of separate datasets from all over the internet.
"By reducing the barriers to developing and using such services, this project will boost the productivity of scientists and engineers working on the problems of today, and better prepare them to tackle the new problems of tomorrow, " Stubbs said.
Expanding volunteer computing
Volunteer computing uses donated computing time on consumer devices such as home computers and smartphones to conduct scientific investigations. Early successes from this approach include the discovery of the structure of an enzyme involved in reproduction of HIV by FoldIt participants; and the detection of pulsars using Einstein@Home.
Volunteer computing can provide greater computing power, at lower cost, than conventional approaches such as organizational computing centers and commercial clouds, but participation in volunteer computing efforts is yet to reach its full potential.
TACC is partnering with the University of California at Berkeley and Purdue University to build new capabilities for BOINC (the most common software framework used for volunteer computing) to grow this promising mode of distributed computing. The project involves two complementary development efforts. D'abord, it adds BOINC-based volunteer computing conduits to two major high-performance computing providers:TACC and nanoHUB, a web portal for nano science that provides computing capabilities. De cette façon, the project benefits the thousands of scientists who use these facilities and creates technologies that make it easy for other HPC providers to add their own volunteer computing capability to their systems.
Seconde, the team will develop a unified interface for volunteer computing, tentatively called Science United, where donors can register to participate and scientists can market their volunteer computing projects to the public.
TACC is currently setting up a BOINC server on Jetstream and using containerization technologies, such as Docker and VirtualBox, to build and package popular applications that can run in high-throughput computing mode on the devices of volunteers. Initial applications being tested include AutoDock Vina, used for drug discovery, and OpenSees, used by the natural hazards community. As a next step, TACC will develop the plumbing required for selecting and routing qualified jobs from TACC resources to the BOINC server.
"By creating a huge pool of low-cost computing power that will benefit thousands of scientists, and increasing public awareness of and interest in science, the project plans to establish volunteer computing as a central and long-term part of the U.S. scientific cyber infrastructure, " said David Anderson, the lead principal investigator on the project from UC Berkeley.














