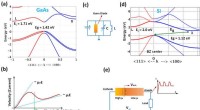
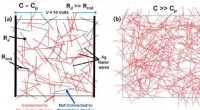
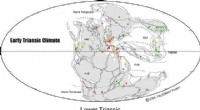
Les algorithmes d’apprentissage automatique (ML) sont aussi efficaces que les données sur lesquelles ils sont formés. Si l'ensemble de formation est biaisé, le modèle ML le sera également. Cela peut conduire à des prédictions inexactes et à des décisions injustes.
Un ensemble de formation peut devenir biaisé de plusieurs manières. Certaines des causes les plus courantes comprennent :
* Biais d'échantillonnage : Cela se produit lorsque l'ensemble de formation n'est pas représentatif de la population sur laquelle le modèle ML sera utilisé. Par exemple, si un ensemble de formation pour un système de reconnaissance faciale est uniquement composé d’images d’hommes blancs, le système sera alors moins précis dans la reconnaissance des femmes et des personnes de couleur.
* Biais de sélection : Cela se produit lorsque le processus de collecte de données privilégie certains échantillons par rapport à d’autres. Par exemple, si une enquête est envoyée uniquement aux personnes qui ont déjà exprimé leur intérêt pour un produit particulier, les résultats de l’enquête seront alors biaisés en faveur des personnes déjà susceptibles d’acheter le produit.
* Biais de mesure : Cela se produit lorsque le processus de collecte de données introduit des erreurs ou des distorsions. Par exemple, si une question d’enquête est formulée d’une manière qui amène les gens à donner une certaine réponse, alors les résultats de l’enquête seront biaisés en faveur de cette réponse.
Il est important d'être conscient du potentiel de biais dans les ensembles de formation ML et de prendre des mesures pour l'atténuer. Certaines des mesures qui peuvent être prises pour réduire les préjugés comprennent :
* Utiliser un ensemble de formations diversifié : L'ensemble de formation doit inclure des données provenant de diverses sources et doit être représentatif de la population sur laquelle le modèle ML sera utilisé.
* Utiliser des méthodes de collecte de données impartiales : Le processus de collecte de données doit être conçu de manière à éviter les biais d’échantillonnage, les biais de sélection et les biais de mesure.
* Auditer régulièrement l'ensemble de formation : L’ensemble de formation doit être audité régulièrement pour identifier et corriger les préjugés qui auraient pu s’y glisser.
En prenant ces mesures, vous pouvez contribuer à garantir que vos modèles ML sont précis et équitables.
Comment développer de nouveaux médicaments sur la base d'ensembles de données fusionnés
La fusion d’ensembles de données peut constituer un moyen puissant d’identifier de nouvelles cibles médicamenteuses et de développer de nouveaux médicaments. En combinant des données provenant de différentes sources, les chercheurs peuvent acquérir une compréhension plus complète du processus pathologique et identifier les cibles potentielles qui auraient pu être manquées en examinant chaque ensemble de données individuellement.
Il existe un certain nombre de défis associés à la fusion d’ensembles de données, notamment :
* Hétérogénéité des données : Les ensembles de données peuvent être collectés à l'aide de différentes méthodes, avoir différents formats et contenir différentes variables. Cela peut rendre difficile la fusion des ensembles de données de manière significative et précise.
* Qualité des données : Les ensembles de données peuvent contenir des erreurs ou des données manquantes. Il peut donc être difficile de tirer des conclusions précises à partir de l’ensemble de données fusionné.
* Confidentialité des données : Les ensembles de données peuvent contenir des informations sensibles qui doivent être protégées. Cela peut rendre difficile le partage de l’ensemble de données fusionné avec d’autres chercheurs.
Malgré ces défis, la fusion d’ensembles de données peut s’avérer un outil précieux pour la découverte de médicaments. En abordant soigneusement les défis, les chercheurs peuvent créer des ensembles de données fusionnés qui peuvent conduire à de nouvelles connaissances et au développement de nouveaux médicaments.
Voici quelques conseils pour développer de nouveaux médicaments basés sur des ensembles de données fusionnés :
* Commencez par une question de recherche claire. Qu’espérez-vous apprendre de l’ensemble de données fusionné ? Cela vous aidera à concentrer vos efforts de collecte et d’analyse de données.
* Identifier et collecter les ensembles de données pertinents. Assurez-vous que les ensembles de données sont pertinents par rapport à votre question de recherche et qu'ils contiennent les données dont vous avez besoin.
* Évaluer la qualité des données. Vérifiez les ensembles de données pour les erreurs et les données manquantes. Assurez-vous que les données sont exactes et fiables.
* Fusionner les ensembles de données. Il existe différentes manières de fusionner des ensembles de données. Choisissez la méthode la plus adaptée à vos données.
* Analyser l'ensemble de données fusionné. Utilisez des méthodes statistiques et d'apprentissage automatique pour analyser l'ensemble de données fusionné. Recherchez des modèles et des tendances qui peuvent indiquer de nouvelles cibles médicamenteuses.
* Validez vos résultats. Menez des expériences pour valider vos résultats. Assurez-vous que les nouvelles cibles médicamenteuses sont réellement efficaces dans le traitement de la maladie.
En suivant ces conseils, vous pouvez augmenter vos chances de développer de nouveaux médicaments basés sur des ensembles de données fusionnés.