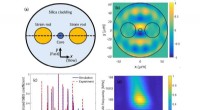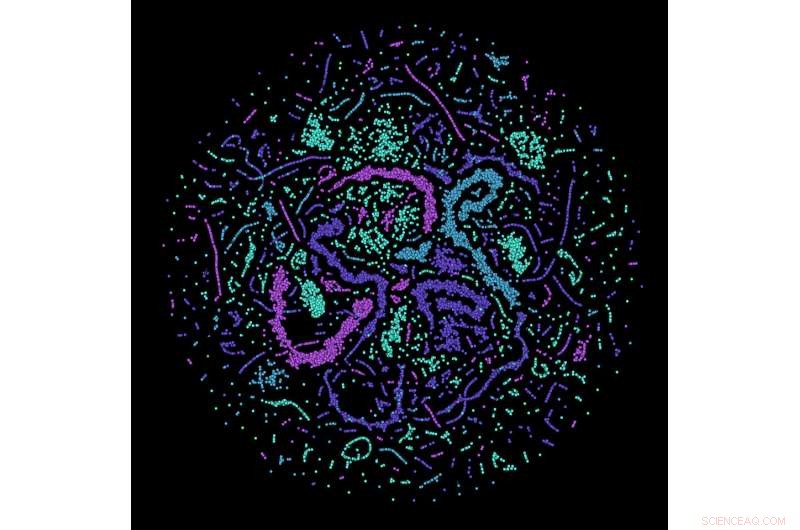
Apprentissage de la correction d'erreur quantique :l'image visualise l'activité des neurones artificiels dans le réseau de neurones des chercheurs d'Erlangen pendant qu'il résout sa tâche. Crédit :Institut Max Planck pour la science de la lumière
Les ordinateurs quantiques pourraient résoudre des tâches complexes qui dépassent les capacités des ordinateurs conventionnels. Cependant, les états quantiques sont extrêmement sensibles aux interférences constantes de leur environnement. Le plan est de lutter contre cela en utilisant une protection active basée sur la correction d'erreur quantique. Florian Marquardt, Directeur à l'Institut Max Planck pour la science de la lumière, et son équipe ont maintenant présenté un système de correction d'erreur quantique capable d'apprendre grâce à l'intelligence artificielle.
En 2016, le programme informatique AlphaGo a remporté quatre des cinq matchs de Go contre le meilleur joueur humain du monde. Étant donné qu'un jeu de Go a plus de combinaisons de mouvements qu'il n'y a d'atomes estimés dans l'univers, cela nécessitait plus qu'une simple puissance de traitement. Plutôt, AlphaGo a utilisé des réseaux de neurones artificiels, qui peuvent reconnaître des modèles visuels et sont même capables d'apprendre. Contrairement à un humain, le programme a pu pratiquer des centaines de milliers de jeux en peu de temps, surpassant finalement le meilleur joueur humain. Maintenant, les chercheurs basés à Erlangen utilisent des réseaux de neurones de ce type pour développer un apprentissage par correction d'erreurs pour un ordinateur quantique.
Les réseaux de neurones artificiels sont des programmes informatiques qui imitent le comportement de cellules nerveuses interconnectées (neurones) - dans le cas de la recherche à Erlangen, environ deux mille neurones artificiels sont connectés les uns aux autres. "Nous prenons les dernières idées de l'informatique et les appliquons aux systèmes physiques, " explique Florian Marquardt. " Ce faisant, nous bénéficions de progrès rapides dans le domaine de l'intelligence artificielle."
Les réseaux de neurones artificiels pourraient surpasser d'autres stratégies de correction d'erreurs
Le premier domaine d'application sont les ordinateurs quantiques, comme le montre l'article récent, qui comprend une contribution importante de Thomas Fösel, doctorant à l'Institut Max Planck d'Erlangen. Dans le journal, l'équipe démontre que les réseaux de neurones artificiels avec une architecture inspirée d'AlphaGo sont capables d'apprendre par eux-mêmes comment effectuer une tâche qui sera essentielle pour le fonctionnement des futurs ordinateurs quantiques :la correction d'erreur quantique. Il y a même la perspective que, avec une formation suffisante, cette approche surpassera les autres stratégies de correction d'erreurs.
Pour comprendre de quoi il s'agit, vous devez examiner le fonctionnement des ordinateurs quantiques. La base de l'information quantique est le bit quantique, ou qubit. Contrairement aux bits numériques conventionnels, un qubit peut adopter non seulement les deux états zéro et un, mais aussi des superpositions des deux états. Dans le processeur d'un ordinateur quantique, il y a même plusieurs qubits superposés dans le cadre d'un état conjoint. Cet enchevêtrement explique l'énorme puissance de traitement des ordinateurs quantiques lorsqu'il s'agit de résoudre certaines tâches complexes pour lesquelles les ordinateurs conventionnels sont voués à l'échec. L'inconvénient est que l'information quantique est très sensible au bruit de son environnement. Ceci et d'autres particularités du monde quantique signifient que l'information quantique a besoin de réparations régulières, c'est-à-dire correction d'erreur quantique. Cependant, les opérations que cela nécessite sont non seulement complexes mais doivent également laisser intacte l'information quantique elle-même.
La correction d'erreur quantique est comme un jeu de Go avec des règles étranges
"Vous pouvez imaginer les éléments d'un ordinateur quantique comme étant comme une planche de Go, " dit Marquardt, aller à l'idée centrale de son projet. Les qubits sont répartis sur le plateau comme des pièces. Cependant, il y a certaines différences essentielles par rapport à un jeu de go classique :toutes les pièces sont déjà réparties sur le plateau, et chacun d'eux est blanc d'un côté et noir de l'autre. Une couleur correspond à l'état zéro, l'autre à l'un, et un mouvement dans un jeu de Go quantique implique de retourner des pièces. Selon les règles du monde quantique, les pièces peuvent aussi adopter des coloris gris mélangés, qui représentent la superposition et l'intrication d'états quantiques.
Quand il s'agit de jouer au jeu, un joueur - nous l'appellerons Alice - effectue des mouvements destinés à préserver un motif représentant un certain état quantique. Ce sont les opérations de correction d'erreur quantique. En attendant, son adversaire fait tout ce qu'il peut pour détruire le motif. Cela représente le bruit constant de la pléthore d'interférences que les vrais qubits subissent de leur environnement. En outre, un jeu de go quantique est rendu particulièrement difficile par une règle quantique particulière :Alice n'est pas autorisée à regarder le plateau pendant la partie. Tout aperçu qui lui révèle l'état des pièces de qubit détruit l'état quantique sensible que le jeu occupe actuellement. La question est :comment peut-elle faire les bons gestes malgré cela ?
Les qubits auxiliaires révèlent des défauts dans l'ordinateur quantique
Dans les ordinateurs quantiques, ce problème est résolu en positionnant des qubits supplémentaires entre les qubits qui stockent les informations quantiques réelles. Des mesures ponctuelles peuvent être effectuées pour surveiller l'état de ces qubits auxiliaires, permettant au contrôleur de l'ordinateur quantique d'identifier où se trouvent les défauts et d'effectuer des opérations de correction sur les qubits porteurs d'informations dans ces zones. Dans notre jeu de Go quantique, les qubits auxiliaires seraient représentés par des pièces supplémentaires réparties entre les pièces de jeu réelles. Alice est autorisée à regarder de temps en temps, mais seulement à ces pièces auxiliaires.
Dans les travaux des chercheurs d'Erlangen, Le rôle d'Alice est joué par des réseaux de neurones artificiels. L'idée est que, par la formation, les réseaux deviendront si bons dans ce rôle qu'ils pourront même dépasser les stratégies de correction conçues par des esprits humains intelligents. Cependant, lorsque l'équipe a étudié un exemple impliquant cinq qubits simulés, un nombre encore gérable pour les ordinateurs conventionnels, ils ont pu montrer qu'un seul réseau de neurones artificiels ne suffit pas. Comme le réseau ne peut recueillir que de petites quantités d'informations sur l'état des bits quantiques, ou plutôt le jeu de Go quantique, il ne dépasse jamais le stade des essais et erreurs aléatoires. Finalement, ces tentatives détruisent l'état quantique au lieu de le restaurer.
Un réseau de neurones utilise ses connaissances préalables pour en former un autre
La solution se présente sous la forme d'un réseau de neurones supplémentaire qui agit comme un enseignant pour le premier réseau. Avec sa connaissance préalable de l'ordinateur quantique à contrôler, ce réseau d'enseignants est capable de former l'autre réseau, son élève, et ainsi de guider ses tentatives vers une correction quantique réussie. D'abord, cependant, le réseau d'enseignants lui-même a besoin d'en apprendre suffisamment sur l'ordinateur quantique ou le composant de celui-ci qui doit être contrôlé.
En principe, les réseaux de neurones artificiels sont entraînés à l'aide d'un système de récompense, tout comme leurs modèles naturels. La récompense réelle est fournie pour restaurer avec succès l'état quantique d'origine par correction d'erreur quantique. "Toutefois, si seulement la réalisation de cet objectif à long terme était récompensée, il arriverait trop tard dans les nombreuses tentatives de correction, " explique Marquardt. Les chercheurs d'Erlangen ont donc développé un système de récompense qui, même au stade de la formation, incite le réseau de neurones des enseignants à adopter une stratégie prometteuse. Dans le jeu de Go quantique, ce système de récompense fournirait à Alice une indication de l'état général du jeu à un moment donné sans en dévoiler les détails.
Le réseau étudiant peut surpasser son enseignant par ses propres actions
"Notre premier objectif était que le réseau d'enseignants apprenne à effectuer avec succès des opérations de correction d'erreurs quantiques sans autre assistance humaine, " dit Marquardt. Contrairement au réseau des élèves de l'école, le réseau d'enseignants peut le faire en se basant non seulement sur les résultats des mesures, mais aussi sur l'état quantique global de l'ordinateur. Le réseau d'élèves formé par le réseau d'enseignants sera alors tout aussi bon dans un premier temps, mais peut devenir encore meilleur par ses propres actions.
En plus de la correction d'erreurs dans les ordinateurs quantiques, Florian Marquardt envisage d'autres applications pour l'intelligence artificielle. À son avis, la physique offre de nombreux systèmes qui pourraient bénéficier de l'utilisation de la reconnaissance de formes par des réseaux de neurones artificiels.