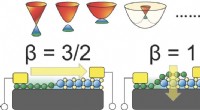
A gauche, EdgeConv, une méthode développée au MIT, trouve avec succès des parties significatives de formes 3D, comme la surface d'une table, ailes d'avion, et les roues d'une planche à roulettes. À droite se trouve la comparaison vérité terrain. Crédit : Institut de technologie du Massachusetts
Si vous avez déjà vu une voiture autonome dans la nature, vous pourriez vous poser des questions sur ce cylindre en rotation au-dessus.
C'est un "capteur lidar, " et c'est ce qui permet à la voiture de naviguer dans le monde. En envoyant des impulsions de lumière infrarouge et en mesurant le temps qu'il leur faut pour rebondir sur des objets, le capteur crée un "nuage de points" qui crée un instantané en 3D de l'environnement de la voiture.
Il est difficile de donner un sens aux données brutes de nuages de points, et avant l'ère de l'apprentissage automatique, il fallait traditionnellement que des ingénieurs hautement qualifiés spécifient de manière fastidieuse les qualités qu'ils voulaient capturer à la main. Mais dans une nouvelle série d'articles du Laboratoire d'informatique et d'intelligence artificielle (CSAIL) du MIT, les chercheurs montrent qu'ils peuvent utiliser l'apprentissage en profondeur pour traiter automatiquement les nuages de points pour un large éventail d'applications d'imagerie 3D.
"Dans la vision par ordinateur et l'apprentissage automatique aujourd'hui, 90 pour cent des avancées ne concernent que les images bidimensionnelles, " dit le professeur du MIT Justin Solomon, qui était l'auteur principal de la nouvelle série d'articles dirigée par Ph.D. étudiant Yue Wang. "Notre travail vise à répondre à un besoin fondamental de mieux représenter le monde 3D, avec une application non seulement dans la conduite autonome, mais n'importe quel domaine qui nécessite de comprendre les formes 3D."
La plupart des approches précédentes n'ont pas été particulièrement efficaces pour capturer les modèles de données nécessaires pour obtenir des informations significatives à partir d'un ensemble de points 3D dans l'espace. Mais dans l'un des papiers de l'équipe, ils ont montré que leur méthode "EdgeConv" d'analyse des nuages de points à l'aide d'un type de réseau de neurones appelé réseau de neurones convolutif à graphe dynamique leur permettait de classer et de segmenter des objets individuels.
"En construisant des "graphiques" de points voisins, l'algorithme peut capturer des modèles hiérarchiques et donc déduire plusieurs types d'informations génériques qui peuvent être utilisées par une myriade de tâches en aval, " dit Wadim Kehl, un scientifique en apprentissage automatique du Toyota Research Institute qui n'a pas participé aux travaux.
En plus de développer EdgeConv, l'équipe a également exploré d'autres aspects spécifiques du traitement des nuages de points. Par exemple, l'un des défis est que la plupart des capteurs changent de perspective lorsqu'ils se déplacent dans le monde en 3D; chaque fois que nous prenons un nouveau scan du même objet, sa position peut être différente de la dernière fois que nous l'avons vue. Pour fusionner plusieurs nuages de points en une seule vue détaillée du monde, vous devez aligner plusieurs points 3D dans un processus appelé « enregistrement ».
L'enregistrement est vital pour de nombreuses formes d'imagerie, des données satellitaires aux procédures médicales. Par exemple, lorsqu'un médecin doit effectuer plusieurs examens d'imagerie par résonance magnétique d'un patient au fil du temps, l'enregistrement est ce qui permet d'aligner les scans pour voir ce qui a changé.
« L'enregistrement est ce qui nous permet d'intégrer des données 3D provenant de différentes sources dans un système de coordonnées commun, " dit Wang. " Sans elle, nous ne serions pas en mesure d'obtenir des informations aussi significatives de toutes ces méthodes qui ont été développées. »
Le deuxième article de Solomon et Wang démontre un nouvel algorithme d'enregistrement appelé « Deep Closest Point » (DCP) qui permet de mieux trouver les motifs distinctifs d'un nuage de points, points, et des bords (appelés « entités locales ») afin de l'aligner avec d'autres nuages de points. Ceci est particulièrement important pour des tâches telles que permettre aux voitures autonomes de se situer dans une scène ("localisation"), ainsi que pour les mains robotiques pour localiser et saisir des objets individuels.
Une limitation de DCP est qu'il suppose que nous pouvons voir une forme entière au lieu d'un seul côté. Cela signifie qu'il ne peut pas gérer la tâche plus difficile d'aligner des vues partielles de formes (appelée « enregistrement partiel à partiel »). Par conséquent, dans un troisième article, les chercheurs ont présenté un algorithme amélioré pour cette tâche qu'ils appellent le réseau d'enregistrement partiel (PRNet).
Solomon dit que les données 3D existantes ont tendance à être « assez désordonnées et non structurées par rapport aux images et photographies 2D ». Son équipe a cherché à comprendre comment obtenir des informations significatives à partir de toutes ces données 3D désorganisées sans l'environnement contrôlé qu'exigent désormais de nombreuses technologies d'apprentissage automatique.
Une observation clé derrière le succès de DCP et PRNet est l'idée qu'un aspect critique du traitement des nuages de points est le contexte. Les caractéristiques géométriques du nuage de points A qui suggèrent les meilleures façons de l'aligner sur le nuage de points B peuvent être différentes des caractéristiques nécessaires pour l'aligner sur le nuage de points C. Par exemple, en inscription partielle, une partie intéressante d'une forme dans un nuage de points peut ne pas être visible dans l'autre, ce qui la rend inutile pour l'enregistrement.
Wang dit que les outils de l'équipe ont déjà été déployés par de nombreux chercheurs dans la communauté de la vision par ordinateur et au-delà. Même les physiciens les utilisent pour une application que l'équipe du CSAIL n'avait jamais envisagée :la physique des particules.
Avancer, les chercheurs espèrent utiliser les algorithmes sur des données du monde réel, y compris les données recueillies à partir de voitures autonomes. Wang dit qu'ils prévoient également d'explorer le potentiel de formation de leurs systèmes en utilisant l'apprentissage auto-supervisé, afin de minimiser le nombre d'annotations humaines nécessaires.
Cette histoire est republiée avec l'aimable autorisation de MIT News (web.mit.edu/newsoffice/), un site populaire qui couvre l'actualité de la recherche du MIT, innovation et enseignement.