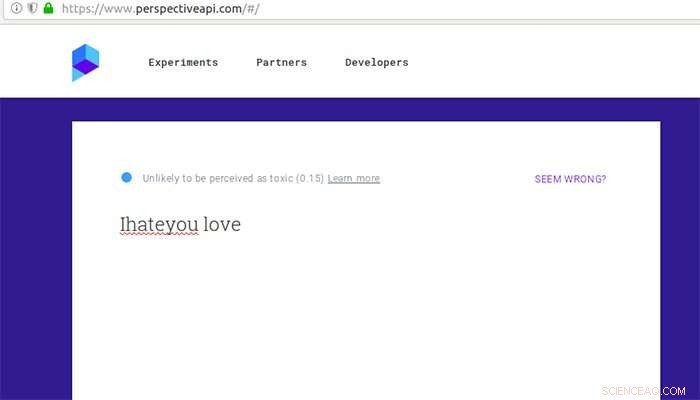
Comment Google Perspective évalue un commentaire autrement jugé toxique après quelques fautes de frappe insérées et un peu d'amour. Crédit :Université Aalto
Les textes et commentaires haineux sont un problème de plus en plus important dans les environnements en ligne, pourtant, aborder le problème endémique repose sur la capacité d'identifier le contenu toxique. Une nouvelle étude du groupe de recherche Secure Systems de l'Université Aalto a découvert des faiblesses dans de nombreux détecteurs d'apprentissage automatique actuellement utilisés pour reconnaître et tenir à distance les discours de haine.
De nombreux réseaux sociaux et plates-formes en ligne populaires utilisent des détecteurs de discours haineux qu'une équipe de chercheurs dirigée par le professeur N. Asokan a maintenant montré comme fragiles et faciles à tromper. Une mauvaise grammaire et une orthographe maladroite, intentionnelle ou non, pourraient rendre les commentaires toxiques sur les réseaux sociaux plus difficiles à repérer pour les détecteurs d'IA.
L'équipe a mis à l'épreuve sept détecteurs de discours haineux à la pointe de la technologie. Tous ont échoué.
Les techniques modernes de traitement du langage naturel (NLP) peuvent classer le texte en fonction de caractères individuels, mots ou phrases. Face à des données textuelles différentes de celles utilisées dans leur formation, ils commencent à tâtonner.
"Nous avons inséré des fautes de frappe, changé les limites des mots ou ajouté des mots neutres au discours de haine original. La suppression des espaces entre les mots était l'attaque la plus puissante, et une combinaison de ces méthodes était efficace même contre le système de classement des commentaires de Google Perspective, " dit Tommi Gröndahl, doctorant à l'Université d'Aalto.
Google Perspective classe la «toxicité» des commentaires à l'aide de méthodes d'analyse de texte. En 2017, des chercheurs de l'Université de Washington ont montré que Google Perspective peut être trompé en introduisant de simples fautes de frappe. Gröndahl et ses collègues ont maintenant découvert que Perspective est depuis devenu résistant aux fautes de frappe simples, mais peut toujours être trompé par d'autres modifications telles que la suppression d'espaces ou l'ajout de mots inoffensifs comme « amour ».