Cette animation montre une série d'événements de collision à STAR, chacun avec des milliers de traces de particules et les signaux enregistrés lorsque certaines de ces particules frappent divers composants du détecteur. Cela devrait vous donner une idée de la complexité du défi de reconstruire un enregistrement complet de chaque particule et des conditions dans lesquelles elle a été créée afin que les scientifiques puissent comparer des centaines de millions d'événements pour rechercher des tendances et faire des découvertes. Crédit :Laboratoire national de Brookhaven
Pour la première fois, les scientifiques ont utilisé le calcul haute performance (HPC) pour reconstruire les données collectées par une expérience de physique nucléaire, une avancée qui pourrait considérablement réduire le temps nécessaire pour rendre des données détaillées disponibles pour les découvertes scientifiques.
Le projet de démonstration a utilisé le supercalculateur Cori du National Energy Research Scientific Computing Center (NERSC), un centre de calcul haute performance au Lawrence Berkeley National Laboratory en Californie, pour reconstruire plusieurs ensembles de données collectées par le détecteur STAR lors de collisions de particules au collisionneur d'ions lourds relativistes (RHIC), une installation de recherche en physique nucléaire au Brookhaven National Laboratory à New York. En exécutant plusieurs tâches de calcul simultanément sur les cœurs de supercalcul alloués, l'équipe a transformé 4,73 pétaoctets de données brutes en 2,45 pétaoctets de données « prêtes pour la physique » en une fraction du temps qu'il aurait fallu en utilisant des ressources informatiques internes à haut débit, même avec un voyage de données transcontinental dans les deux sens.
"La raison pour laquelle c'est vraiment fantastique, " a déclaré le physicien de Brookhaven Jérôme Lauret, qui gère les besoins informatiques de STAR, « est que ces ressources de calcul hautes performances sont élastiques. Vous pouvez appeler pour réserver une grande partie de la puissance de calcul lorsque vous en avez besoin, par exemple, juste avant une grande conférence où les physiciens sont pressés de présenter de nouveaux résultats." Selon Lauret, la préparation des données brutes pour l'analyse prend généralement plusieurs mois, ce qui rend presque impossible de fournir une telle réactivité à court terme. "Mais avec le HPC, peut-être pourriez-vous condenser ce temps de production de plusieurs mois en une semaine. Cela donnerait vraiment du pouvoir aux scientifiques ! »
Cette réalisation met en valeur les capacités synergiques du RHIC et du NERSC—U.S. Département de l'énergie (DOE) Office of Science User Facilities situées dans des laboratoires nationaux gérés par le DOE sur des côtes opposées, connectés par l'un des réseaux de partage de données haute performance les plus étendus au monde, Réseau des sciences de l'énergie du DOE (ESnet), une autre installation utilisateur du DOE Office of Science.
« C'est un modèle d'utilisation clé du calcul haute performance pour les données expérimentales, démontrer que les chercheurs peuvent réaliser leurs campagnes de traitement de données brutes ou de simulation en quelques jours ou semaines à un moment critique au lieu de s'étaler sur des mois sur leurs propres ressources dédiées, " a déclaré Jeff Porter, membre de l'équipe des services de données et d'analyse de la NERSC.
Des milliards de points de données
Pour faire des découvertes en physique au RHIC, les scientifiques doivent trier des centaines de millions de collisions entre des ions accélérés à très haute énergie. STAR, un sophistiqué, instrument électronique de la taille d'une maison, enregistre les débris subatomiques provenant de ces écrasements de particules. Dans les événements les plus énergiques, plusieurs milliers de particules heurtent les composants du détecteur, produisant des affichages de type feu d'artifice de pistes de particules colorées. Mais pour comprendre ce que signifient ces signaux complexes, et ce qu'ils peuvent nous dire sur la forme intrigante de matière créée dans les collisions du RHIC, les scientifiques ont besoin de descriptions détaillées de toutes les particules et des conditions dans lesquelles elles ont été produites. Ils doivent également comparer d'énormes échantillons statistiques provenant de nombreux types différents d'événements de collision.
Le catalogage de ces informations nécessite des algorithmes sophistiqués et un logiciel de reconnaissance de formes pour combiner les signaux des différentes électroniques de lecture, et un moyen transparent de faire correspondre ces données avec les enregistrements des conditions de collision. Toutes les informations doivent ensuite être conditionnées de manière à ce que les physiciens puissent les utiliser pour leurs analyses.

Cori, le plus récent supercalculateur du Centre national de calcul scientifique de la recherche énergétique (NERSC), est un Cray XC40 avec une performance maximale d'environ 30 pétaflops. Crédit :Laboratoire national de Brookhaven
Depuis que RHIC a commencé à fonctionner en 2000, ce traitement de données brutes, ou reconstruction, a été réalisée sur des ressources informatiques dédiées au RHIC et ATLAS Computing Facility (RACF) à Brookhaven. Les clusters de calcul à haut débit (HTC) traitent les données, événement par événement, et écrivez les détails codés de chaque collision dans un espace de stockage de masse centralisé accessible aux physiciens STAR du monde entier.
Mais le défi de suivre les données s'est accru avec les taux de collision en constante amélioration du RHIC et à mesure que de nouveaux composants de détecteur ont été ajoutés. Dans les années récentes, Les ensembles de données brutes annuelles de STAR ont atteint des milliards d'événements avec des tailles de données de l'ordre de plusieurs pétaoctets. L'équipe informatique de STAR a donc étudié l'utilisation de ressources externes pour répondre à la demande d'accès rapide à des données prêtes pour la physique.
De nombreux noyaux font un travail léger
Contrairement aux ordinateurs à haut débit du RACF, qui analysent les événements un par un, Les ressources HPC comme celles du NERSC divisent les gros problèmes en tâches plus petites qui peuvent s'exécuter en parallèle. Le premier défi était donc de « paralléliser » le traitement des données d'événements STAR.
« Nous avons écrit des programmes de workflow qui ont atteint le premier niveau de parallélisation :parallélisation d'événements, " a déclaré Lauret. Cela signifie qu'ils soumettent moins de travaux composés de nombreux événements qui peuvent être traités simultanément sur les nombreux cœurs de calcul HPC.
« Imaginez construire une ville de 100 habitations. Si cela se faisait à haut débit, chaque maison aurait un constructeur effectuant toutes les tâches dans l'ordre - construire les fondations, les murs, etc, " Lauret a déclaré. "Mais avec HPC, nous changeons de paradigme. Au lieu d'un travailleur par maison, nous avons 100 travailleurs par maison, et chaque ouvrier a une tâche :construire les murs ou le toit. Ils travaillent en parallèle, à la fois, et nous assemblons tout ensemble à la fin. Avec cette approche, nous construirons cette maison 100 fois plus vite."
Bien sûr, il faut un peu de créativité pour réfléchir à la façon dont de tels problèmes peuvent être divisés en tâches qui peuvent s'exécuter simultanément au lieu de séquentiellement, ajouta Lauret.
Le HPC permet également de gagner du temps en faisant correspondre les signaux bruts du détecteur avec les données sur les conditions environnementales lors de chaque événement. Pour faire ça, les ordinateurs doivent accéder à une "base de données d'état" - un enregistrement de la tension, Température, pression, et d'autres conditions du détecteur qui doivent être prises en compte pour comprendre le comportement des particules produites dans chaque collision. Au cas par cas, reconstruction à haut débit, les ordinateurs appellent la base de données pour récupérer les données de chaque événement. Mais comme les cœurs HPC partagent une partie de la mémoire, les événements qui se produisent dans le temps peuvent utiliser les mêmes données de condition mises en cache. Moins d'appels à la base de données signifie un traitement plus rapide des données.
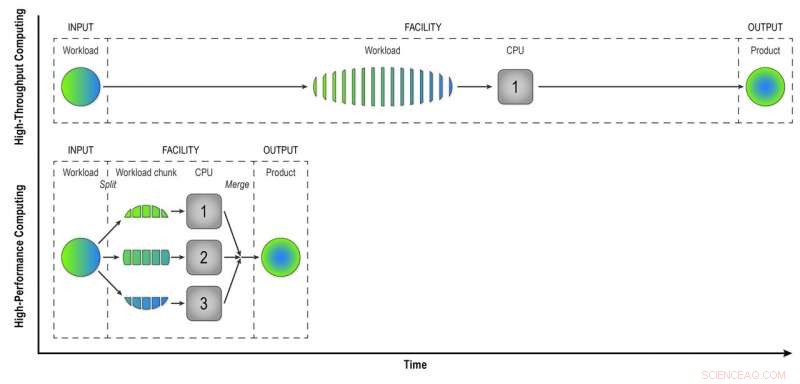
Dans le calcul à haut débit, une charge de travail composée de données provenant de nombreuses collisions STAR est traitée événement par événement de manière séquentielle pour donner aux physiciens des "données reconstruites" - le produit dont ils ont besoin pour analyser complètement les données. Le calcul hautes performances divise la charge de travail en plus petits morceaux qui peuvent être exécutés via des processeurs distincts pour accélérer la reconstruction des données. Dans cette simple illustration, diviser une charge de travail de 15 événements en trois morceaux de cinq événements traités en parallèle donne le même produit en un tiers du temps que la méthode à haut débit. L'utilisation de 32 processeurs sur un supercalculateur comme Cori peut réduire considérablement le temps nécessaire pour transformer les données brutes à partir d'un véritable ensemble de données STAR, avec plusieurs millions d'événements, en informations utiles que les physiciens peuvent analyser pour faire des découvertes. Crédit :Laboratoire national de Brookhaven
Travail d'équipe en réseau
Un autre défi dans la migration de la tâche de reconstruction des données brutes vers un environnement HPC consistait simplement à transférer les données de New York vers les superordinateurs en Californie et inversement. Les ensembles de données d'entrée et de sortie sont énormes. L'équipe a commencé modestement avec une expérience de démonstration de principe (quelques centaines de tâches seulement) pour voir comment leurs nouveaux programmes de flux de travail fonctionneraient.
« Nous avons eu beaucoup d'aide de la part des professionnels du réseautage de Brookhaven, " dit Lauret, " en particulier Mark Lukascsyk, l'un de nos ingénieurs réseau, qui était tellement enthousiasmé par la science et nous a aidés à faire des découvertes." Mustafa Mustafa, et d'autres au NERSC pour optimiser le transfert de données et le flux de travail de bout en bout.
Commencer petit, Augmenter
Après avoir affiné leurs méthodes sur la base des premiers tests, l'équipe a commencé à passer à 6, 400 cœurs de calcul au NERSC, puis de haut en haut et en haut.
"6, 400 cœurs, c'est déjà la moitié de la taille des ressources disponibles pour la reconstruction des données au RACF, " Lauret a déclaré. "Finalement, nous sommes allés à 25, 600 cœurs dans notre test le plus récent." Avec tout prêt à l'avance pour une allocation de temps de réservation à l'avance sur le supercalculateur Cori, "nous avons fait ce test pendant quelques jours et avons réalisé une production complète de données en un rien de temps, " Lauret a déclaré. Selon Porter au NERSC, "Ce modèle est potentiellement assez transformateur, et NERSC a travaillé pour soutenir une telle utilisation des ressources en, par exemple, reliant directement son système de disque hautes performances à l'échelle du centre à son infrastructure de transfert de données et permettant une flexibilité significative dans la façon dont les créneaux de travail peuvent être planifiés. »
L'efficacité de bout en bout de l'ensemble du processus - la durée d'exécution du programme (pas d'inactivité, en attente de ressources informatiques) multiplié par l'efficacité d'utilisation des créneaux de supercalcul alloués et d'obtention d'une sortie utile jusqu'à Brookhaven - était de 98 %.
« Nous avons prouvé que nous pouvons utiliser efficacement les ressources HPC pour éliminer les arriérés de données non traitées et résoudre les demandes de ressources temporaires pour accélérer les découvertes scientifiques, " dit Lauret.
Il explore maintenant des moyens de généraliser le flux de travail à l'Open Science Grid, un consortium mondial qui regroupe les ressources informatiques, afin que l'ensemble de la communauté des physiciens des hautes énergies et nucléaires puisse l'utiliser.