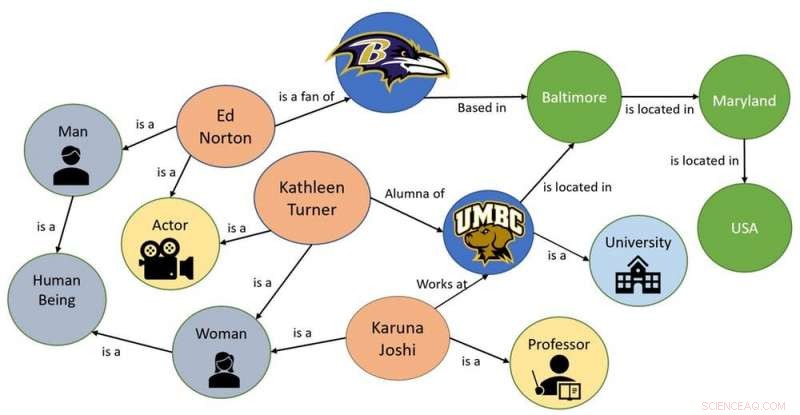
Un exemple de graphe de connaissances simple. Crédit :Karuna Pande Joshi, CC BY-ND
Vous suivez des morceaux de données personnelles, comme des numéros de carte de crédit, préférences d'achat et les articles d'actualité que vous lisez, lorsque vous voyagez sur Internet. Les grandes sociétés Internet gagnent de l'argent avec ce type d'informations personnelles en les partageant avec leurs filiales et des tiers. Les préoccupations du public concernant la confidentialité en ligne ont conduit à des lois conçues pour contrôler qui obtient ces données et comment ils peuvent les utiliser.
La bataille est en cours. Les démocrates du Sénat américain ont récemment présenté un projet de loi prévoyant des sanctions pour les entreprises technologiques qui traitent mal les données personnelles des utilisateurs. Cette loi rejoindrait une longue liste de règles et de réglementations dans le monde entier, y compris la norme de sécurité des données de l'industrie des cartes de paiement qui réglemente les transactions par carte de crédit en ligne, le règlement général sur la protection des données de l'Union européenne, la California Consumer Privacy Act entrée en vigueur en janvier, et la loi américaine sur la protection de la vie privée en ligne des enfants.
Les sociétés Internet doivent respecter ces réglementations ou risquer des poursuites coûteuses ou des sanctions gouvernementales, comme la récente amende de 5 milliards de dollars US imposée à Facebook par la Federal Trade Commission.
Mais il est techniquement difficile de déterminer en temps réel si une violation de la vie privée a eu lieu, un problème qui devient encore plus problématique à mesure que les données Internet évoluent à une échelle extrême. Pour s'assurer que leurs systèmes sont conformes, les entreprises s'appuient sur des experts humains pour interpréter les lois, une tâche complexe et chronophage pour les organisations qui lancent et mettent constamment à jour des services.
Mon groupe de recherche à l'Université du Maryland, Comté de Baltimore, a développé de nouvelles technologies pour les machines afin de comprendre les lois sur la confidentialité des données et de les faire respecter à l'aide de l'intelligence artificielle. Ces technologies permettront aux entreprises de s'assurer que leurs services sont conformes aux lois sur la confidentialité et aideront également les gouvernements à identifier en temps réel les entreprises qui violent les droits à la vie privée des consommateurs.
Aider les machines à comprendre les réglementations
Les gouvernements génèrent des règles de confidentialité en ligne sous forme de documents en texte brut faciles à lire pour les humains mais difficiles à interpréter pour les machines. Par conséquent, les réglementations doivent être examinées manuellement pour s'assurer qu'aucune règle n'est enfreinte lorsque les données privées d'un citoyen sont analysées ou partagées. Cela affecte les entreprises qui doivent désormais se conformer à une forêt de réglementations.
Les règles et réglementations sont souvent ambiguës de par leur conception parce que les sociétés veulent de la flexibilité dans leur mise en œuvre. Les concepts subjectifs tels que le bien et le mal varient selon les cultures et au fil du temps, les lois sont donc rédigées en termes généraux ou vagues pour permettre des modifications futures. Les machines ne peuvent pas traiter cette imprécision - elles fonctionnent avec des 1 et des 0 - elles ne peuvent donc pas « comprendre » la confidentialité comme le font les humains. Les machines ont besoin d'instructions spécifiques pour comprendre les connaissances sur lesquelles se fonde une réglementation.

L'application des chercheurs a extrait automatiquement les règles déontiques, telles que les autorisations et les obligations, de deux règles de confidentialité. Les entités impliquées dans les règles sont surlignées en jaune. Mots modaux permettant d'identifier si une règle est une autorisation, l'interdiction ou l'obligation sont surlignées en bleu. Le gris indique l'aspect temporel ou temporel de la règle. Crédit :Karuna Pande Joshi, CC BY-ND
Une façon d'aider les machines à comprendre un concept abstrait est de construire une ontologie, ou un graphique représentant la connaissance de ce concept. Emprunter les concepts de l'ontologie à la philosophie, nouveaux langages informatiques, comme OWL, ont été développés en IA. Ces langages peuvent définir des concepts et des catégories dans un domaine ou un domaine, montrer leurs propriétés et montrer les relations entre eux. Les ontologies sont parfois appelées « graphes de connaissances, " car ils sont stockés dans des structures de type graphique.
Lorsque mes collègues et moi avons commencé à examiner le défi de rendre les règles de confidentialité compréhensibles par les machines, nous avons déterminé que la première étape serait de capturer toutes les connaissances clés de ces lois et de créer des graphiques de connaissances pour les stocker.
Extraire les termes et règles
Les connaissances clés contenues dans la réglementation se composent de trois parties.
D'abord, il existe des « termes de l'art » :des mots ou des phrases qui ont des définitions précises dans une loi. Ils aident à identifier l'entité que le règlement décrit et nous permettent de décrire ses rôles et responsabilités dans un langage que les ordinateurs peuvent comprendre. Par exemple, du règlement général de l'UE sur la protection des données, nous avons extrait des termes techniques tels que « Consommateurs et fournisseurs » et « Amendes et exécution ».
Prochain, nous avons identifié des règles déontiques :des phrases ou des phrases qui nous fournissent une logique modale philosophique, qui traite du comportement déductif. Les règles déontiques (ou morales) comprennent des phrases décrivant des devoirs ou des obligations et se répartissent principalement en quatre catégories. Les « autorisations » définissent les droits d'une entité/d'un acteur. Les « obligations » définissent les responsabilités d'une entité/d'un acteur. Les « interdictions » sont des conditions ou des actions qui ne sont pas autorisées. Les « dispenses » sont des déclarations facultatives ou non obligatoires.
Pour expliquer cela avec un exemple simple, considérer ce qui suit:

graphique de connaissances pour les réglementations GDPR. Crédit :Karuna Pande Joshi, CC BY-ND
Certaines de ces règles s'appliquent à tout le monde uniformément dans toutes les conditions; tandis que d'autres peuvent s'appliquer partiellement, à une seule entité ou sur la base de conditions acceptées par tous.
Des règles similaires qui décrivent les choses à faire et à ne pas faire s'appliquent aux données personnelles en ligne. Il existe des autorisations et des interdictions pour empêcher les violations de données. Les entreprises qui stockent les données ont des obligations d'assurer leur sécurité. Et il y a des dispenses faites pour les groupes démographiques vulnérables tels que les mineurs.
Mon groupe a développé des techniques pour extraire automatiquement ces règles du règlement et les enregistrer dans un graphe de connaissances.
Troisièmement, nous avons également dû trouver comment inclure les références croisées qui sont souvent utilisées dans les réglementations légales pour référencer le texte dans une autre section de la réglementation ou dans un document séparé. Ce sont des éléments de connaissance importants qui doivent également être stockés dans le graphe de connaissances.
Règles en place, analyse de conformité
Après avoir défini toutes les entités clés, Propriétés, rapports, règles et politiques d'une loi sur la confidentialité des données dans un graphe de connaissances, mes collègues et moi pouvons créer des applications capables de raisonner sur les règles de confidentialité des données à l'aide de ces graphes de connaissances.
Ces applications peuvent réduire considérablement le temps qu'il faudra aux entreprises pour déterminer si elles se conforment aux réglementations en matière de protection des données. Ils peuvent également aider les régulateurs à surveiller les pistes d'audit des données pour déterminer si les entreprises qu'ils supervisent se conforment aux règles.
Cette technologie peut également aider les individus à obtenir un aperçu rapide de leurs droits et responsabilités en ce qui concerne les données privées qu'ils partagent avec les entreprises. Une fois que les machines peuvent rapidement interpréter longtemps, des politiques de confidentialité complexes, les gens pourront automatiser de nombreuses activités de conformité banales qui sont effectuées manuellement aujourd'hui. Ils peuvent également être en mesure de rendre ces politiques plus compréhensibles pour les consommateurs.
Cet article est republié à partir de The Conversation sous une licence Creative Commons. Lire l'article original.