Les racks d'ordinateurs du centre de calcul du CERN ne représentent qu'une fraction du matériel nécessaire pour stocker et traiter les données du LHC. Crédit :Anthony Grossir/CERN
Fin 2018, le Grand collisionneur de hadrons (LHC) a terminé sa deuxième période d'exploitation pluriannuelle ("Run 2") qui a vu la machine atteindre une énergie de collision proton-proton de 13 TeV, le plus élevé jamais atteint par un accélérateur de particules. Au cours de cette course, de 2015 à 2018, Les expériences LHC ont produit des volumes de données sans précédent, les performances de la machine dépassant toutes les attentes.
Cela signifiait une utilisation exceptionnelle de l'informatique, avec de nombreux records battus en termes d'acquisition de données, débits et volumes de données. Le système de stockage avancé du CERN (CASTOR), qui s'appuie sur un backend sur bande pour l'archivage permanent des données, atteint 330 Po de données (équivalent à 330 millions de gigaoctets) stockées sur bande, l'équivalent de plus de 2000 ans d'enregistrement vidéo HD 24h/24 et 7j/7. Rien qu'en novembre 2018, un record de 15,8 Po de données a été enregistré sur bande, un exploit remarquable étant donné qu'il correspond à plus que ce qui a été enregistré au cours de la première année du Run 1 du LHC.
Le système de stockage distribué pour les expériences LHC dépassait 200 Po de stockage brut avec environ 600 millions de fichiers. Ce système (EOS) est basé sur disque et open-source, et a été développé au CERN pour les besoins informatiques extrêmes du LHC. Ainsi que cette, 830 Po de données et 1,1 milliard de fichiers ont été transférés dans le monde entier par le service de transfert de fichiers. Pour faire face à ces défis informatiques et pour mieux accompagner les expériences du CERN lors du Run 2, l'ensemble de l'infrastructure informatique, et notamment les systèmes de stockage, a fait l'objet de mises à niveau et de consolidations majeures au cours des dernières années.
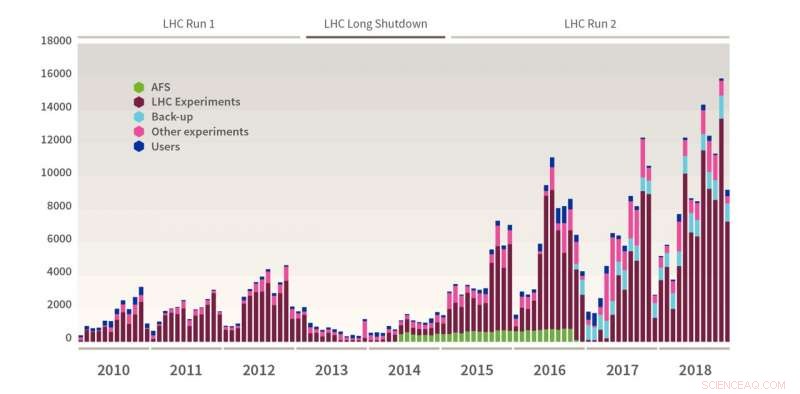
Données (en téraoctets) enregistrées sur bande au CERN mois par mois. Ce graphique montre la quantité de données enregistrées sur bande générées par les expériences LHC, d'autres expériences, diverses sauvegardes et utilisateurs. En 2018, plus de 115 Po de données au total (dont environ 88 Po de données LHC) ont été enregistrées sur bande, avec un pic record de 15,8 PB en novembre. Crédit :Esma Mobs/CERN
De nouvelles activités de recherche et développement informatique ont déjà commencé en vue du Run 3 du LHC (prévu pour 2021 à 2023). "Notre nouveau logiciel, nommé CERN Tape Archive (CTA), est le nouveau système de stockage sur bande pour la copie de conservation des données physiques et un remplacement pour son prédécesseur, CASTOR. L'objectif principal du CTA est d'utiliser plus efficacement les lecteurs de bande, pour gérer le débit de données plus élevé prévu pendant les Run 3 et Run 4 du LHC, " explique German Cancio, qui mène la bande, Section de stockage d'archives et de sauvegardes du département informatique du CERN. Le CTA sera déployé pendant le deuxième long arrêt en cours du LHC (LS2), en remplacement de CASTOR. Par rapport à la dernière année de Run 2, l'archivage des données devrait être deux fois plus élevé au cours du cycle 3 et cinq fois plus élevé ou plus au cours du cycle 4 (prévu pour 2026 à 2029).
L'informatique du LHC continuera d'évoluer. La plupart des données collectées dans le centre de données du CERN sont très précieuses et doivent être préservées et stockées pour les futures générations de physiciens. Le service informatique du CERN profitera donc de LS2, la maintenance actuelle et la mise à niveau du complexe d'accélérateurs, pour effectuer la consolidation requise de l'infrastructure informatique. Ils mettront à niveau l'infrastructure de stockage et les logiciels pour faire face aux probables problèmes d'évolutivité et de performances lorsque le LHC redémarrera en 2021 pour la phase 3.